
목차
0. Abstract
1. Introduction
2. The Dataset
3. The Architecture
3.1 ReLU Nonlinearity
3.2 Training on Multiple GPUs
3.3 Local Response Normalization
3.4 Overlapping Pooling
3.5 Overall Architecture
4. Reduce Overfitting
4.1 Data Augmentation
4.2 Dropout
5. Details of learning
6. Results
6.1 Qualitative Evaluations
7. Discussion
0. Abstract

neural network
- 60M parameter
- 650,000 neurons
- 5 convolutional layers
- max pooling layers
- 3 fully connected layers (마지막 1000 softmax)
과적합 방지: dropout
속도 향상: 불포화 뉴런, GPU
1. Introduction
최근 객체 인지에서 ML이 필수적으로 사용됨
이를 더 발전시키기 위해
- 더 큰 데이터셋 이용
- 더 강력한 모델 학습
- 과적합 방지를 위해 더 나은 기술 사용
최근까지 labeling된 이미지 데이터 셋이 비교적 작았음 – 단순 인지 업무 정도 (label 보전 변형 augmentation 이용)
실제 setting으로는 더 많은 데이터셋 필요
> 최근에서 labeling된 millions의 이미지 데이터셋 수집이 가능해짐 (ex. LabelMe, ImageNet)
millions의 이미지에서 수천개를 분류하는 것을 학습하기 위해, 더 큰 학습 용량을 가진 모델이 필요
> CNN
- 깊이로 용량 조절 가능
- 이미지에 강하고 맞는 가정을 만들 수 있음
- parameter 숫자가 작음, 학습이 쉬움
최신 GPU + overfitting 없이 모델 학습에 충분한 label 존재
기여
- ILSVRC-2010, ILSVRC-2012 ImageNet 데이터를 CNN에 학습 > 최고의 결과
- 최적화 GPU
- 학습 시간은 적음
- overfitting 방지
“5 convolutional layer + 3 fully connected layer” 구성이 중요!
2. The Dataset
ImageNet 15M labeled images, 22,000 categories
수집 경로: web + human labelers
ILSVRC
- ImageNet 기반 1000개의 각 category별 1000 images
- 1.2M training images, 50,000 validation images, 150,000 test images
- ImageNet-2010, ImageNet-2012 참여
- 2 error rate (top-1, top5 (정답이 model이 예측한 5개의 보기 중에 존재 여부))
image down-sampling (256 * 256)
- 가로, 세로 중 짧은 부분 선 256
- 결과 이미지의 중간을 256 * 256 crop
- training set의 각 pixel에 평균을 뺌 (추가 전처리 없음)
- 픽셀의 중간 raw RGB에서 네트워크 학습
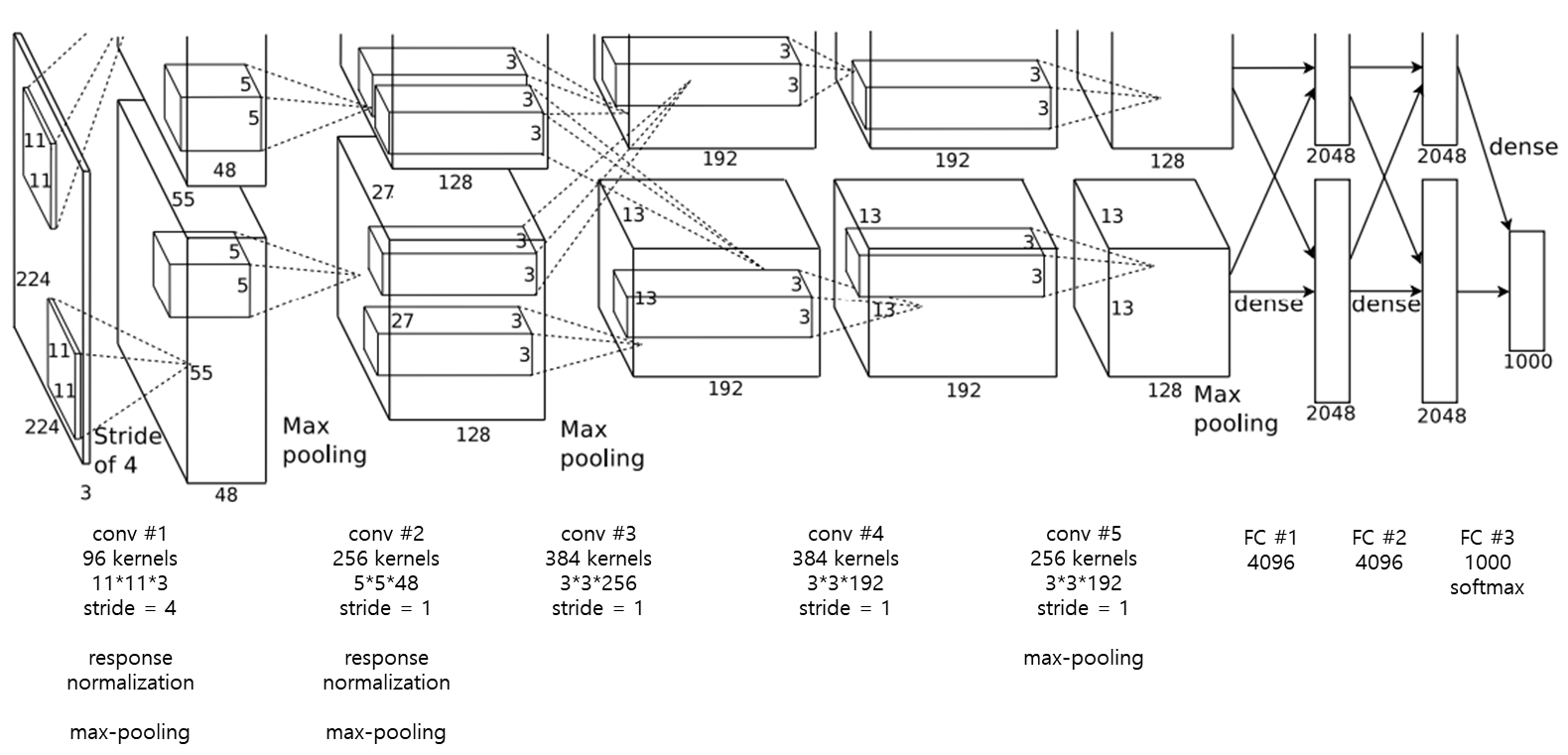
3. The Architecture
8개의 학습된 layer (5 convolutional layer + 3 fully connected layer)

3.1 ReLU Nonlinearity

gradient descent의 학습 시간에서, 비선형 포화가 비선형 불포화 (𝑓(𝑥)=max(0, 𝑥)) 보다 느림
> 비선형 Rectified Linear Units (ReLU) 제안
CNN + ReLU 학습속도가 더 빠름
큰 dataset으로 학습하여 큰 dataset에 적용할 때 영향력이 좋음
3.2 Training on Multiple GPUs
GTX 580 GPU 1개: 3GB memory
- 모델 학습에 최대 사이즈에 제한
- 1.2M 학습 예시를 네트워크에 학습하는데 GPU 1개로 부족
2개의 GPU에 퍼뜨려 적용하여 학습시간 단축
- 최근 GPU는 cross-GPU 병렬화에 잘 맞춰짐
- 서로 다른 메모리끼리 읽고 쓰기 가능
- 각 GPU에 kernels의 반만 넣으면 됨
- 각 GPU는 특정 layer에서 소통 (계산 가능한 양의 비율까지 소통만 허용)

3.3 Local Response Normalization
ReLU는 포화를 방지하기 위한 input normalization 필요 없음
적어도 몇몇의 학습 예시들은 ReLU의 긍정적 input들을 생성한다면, 해당 neuro에서 학습할 것
하지만 여전히 local normalization이 일반화에 도움을 줌
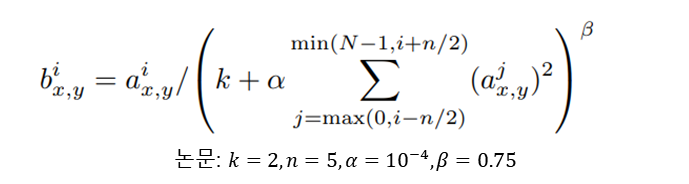
몇몇의 layer의 비선형 ReLU 적용 후에 normalization 적용

3.4 Overlapping Pooling
CNN의 pooling layer: 같은 kernel map의 인접한 neuron 그룹의 output을 요약
전통적) 인접한 pooling unit으로 요약된 그룹은 overlap되지 않음

3.5 Overall Architecture
8 layer = 5 convolution layer + 3 fully connected layer (마지막 1000 softmax)
- 모든 layer에 대해 비선형 ReLU 적용
- 2, 4, 5 convolution은 같은 GPU를 사용하는 kernel map인 이전 layer에만 연결
- 3 convolution은 두번째 layer의 모든 kernel map과 연결
- 모든 fully connected layer는 이전 layer의 모든 neuron과 연결
4. Reduce Overfitting
60M parameters
4.1 Data Augmentation
가장 간단하고 흔한 이미지 데이터 overfitting 감소 방법은 label-보존 변형을 이용해서 인위적으로 데이터셋을 늘리는 것
- 2개의 별개의 data augmentation 이용
- 매우 작은 게산으로 기존 이미지에서 변형된 이미지 생성 (저장 필요 없음)
- CPU를 이용하므로 계산을 무료!
1st form of data augmentation
- generating image translations
- horizontal reflections
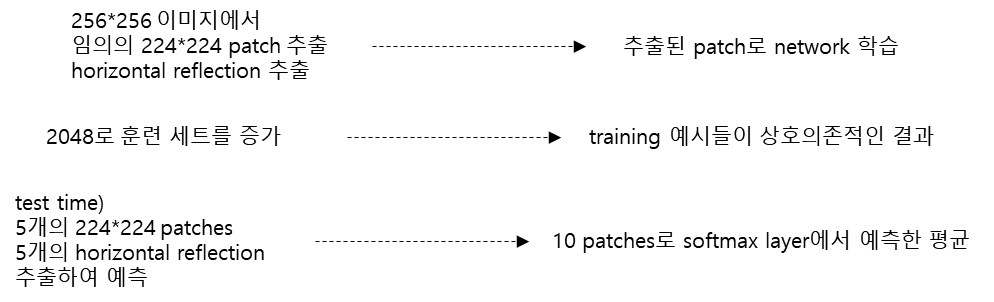
2nd form of data augmentation
- training 이미지의 RGB channel의 강도 변화
- ImageNet 훈련 set의 RGB 픽셀 값의 PCA 적용

top-1 error rate 1.0% 감소
4.2 Dropout
다른 model을 합쳐서 예측하는 것은 test error 감소에 매우 성공적
하지만, 큰 neural network에서 너무 비쌈
Dropout: 0.5의 확률로 각 hidden neuron의 output을 0으로 함
- forward pass, back propagation 참여하지 않음
- input이 나타날 때마다 neural network가 다른 구조에 샘플링 (가중치 공유)
- 더 튼튼한 feature 학습
- 다른 임의의 뉴런 부분집합으로 결합
test time) 모든 neuron을 사용하지만 output에 0.5를 곱함
5. Details of learning
확률론적 gradient descent를 이용하여 model 학습
- batch size = 128
- momentum = 0.9
- weight decay = 0.0005 (reduce model training error)
- w’s weight update rule
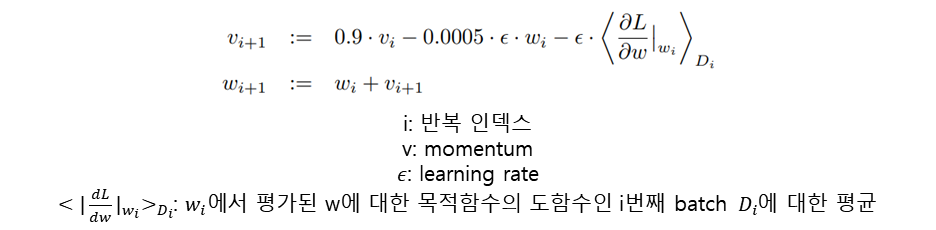
- 각 layer의 weight 초기화: 평균이 0인 Gaussian 분포, 표준편차: 0.01
- neuron bias 초기화: 1 (2, 4, 5 convolution layer, fully connected layer)
- 기존 layer의 neuron bias 초기화: 0
- 모든 layer에 동일 learning rate 이용: 학습하면서 직접 조정 (validation error rate가 현재 learning rate에서 나아지지 않으면, (learning rate)⁄10)
- learning rate 초기화: 0.01 (종료 전 3번 감소)
- 1.2M 훈련 이미지, 대략 90 cycle 학습 (NVIDIA GTX 580 3GB GPUs 2개에서 5~6일 소요)
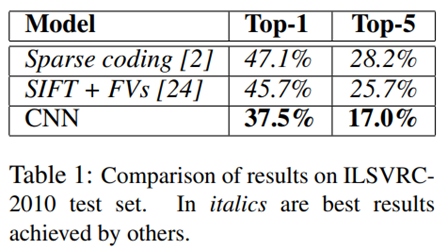
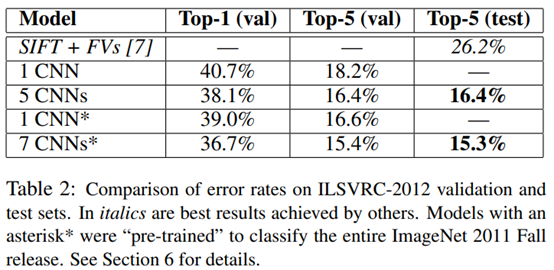
6. Results
ILSVRC-2010
ILSVRC-2012
6.1 Qualitative Evaluations


7. Discussion




