
목차
0. Abstract
1. Introduction
2. RNN Encoder-Decoder
2.1 Preliminary: Recurrent Neural Networks
2.2 RNN Encoder-Decoder
2.3 Hidden Unit that Adaptively Remembers and Forgets
3. Statistical Machine Translation
3.1 Scoring Phrase Pairs with RNN Encoder-Decoder
3.2 Related Approaches: Neural Networks in Machine Translation
4. Experiments
4.1 Data and Baseline System
4.1.1 RNN Encoder-Decoder
4.1.2 Neural Language Model
4.2 Quantitative Analysis
4.3 Qualitative Analysis
4.4 Word and Phrase Representations
5. Conclusion
0. Abstract
심층신경망은 이의제기 인식, 음성 인식에서 성공적
= 자연어처리(NLP)에서 성공적
통계적 기계번역(SMT)에서 성공적
SMT 위한 신경망 사용 연구라인을 따라,
기존의 구문 기반 SMT system 일부로 사용될 수 있는 새로운 신경망 아키텍처에 초점
새로운 RNN Encoder-Decoder model 제안
2. RNN Encoder-Decoder
2.1 Preliminary: Recurrent Neural Networks
RNN은 hidden state h와 가변길이 sequence X=(X1, …, Xt)에서 작동하는 선택적 출력 y로 구성된 신경망
각 시간 단계 t에서 hidden state h(t) update
h(t)=f(h(t-1), xt)
RNN은 sequence의 다음 symbol을 예측하도록 훈련되어 sequence에 대한 확률 분포 학습 가능
이때 각 시간 단계 t의 출력은 조건부분포 p(xt |x(t-1), …, x1)
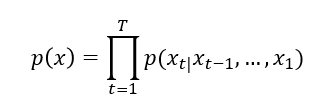
2.2 RNN Encoder-Decoder
확률론적 관점에서 논문에서 제안한 모델은 또 다른 가변 길이 sequence를 조건으로 하는 가변길이 sequence에 대한 조건부분포를 학습하는 일반적인 방법(입력과 출력 sequence길이를 뜻하는 T와 T'의 길이는 다를 수 있음)
p(y1, …, yT′ |x1, …, xT)
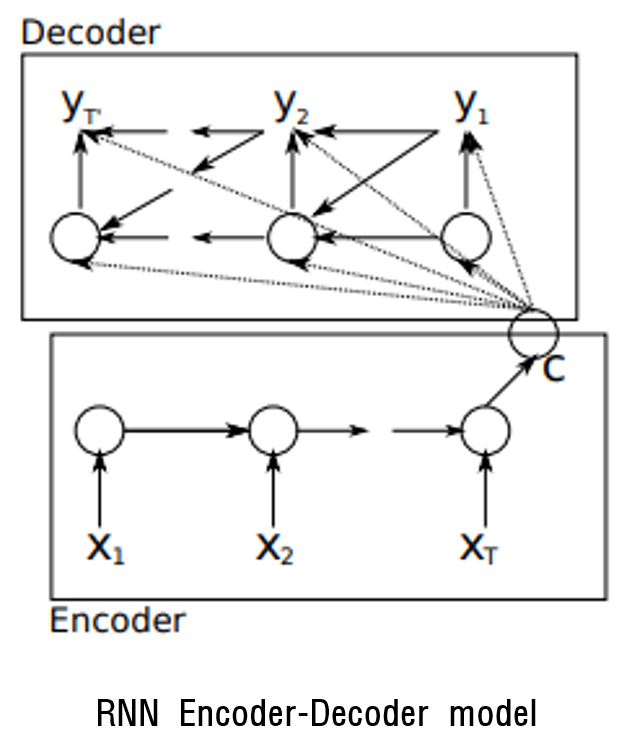
Encoder: 입력 sequence x의 각 기호를 순차적으로 읽는 RNN
각 기호를 읽을 때 RNN의 hidden state는 변경
마지막 RNN의 hidden state는 전체 입력 sequence의 요약 c(=context vector)
Decoder: hidden state h(t)가 주어지면 다음 symbol yt를 예측하여 출력 sequence를 생성하도록 훈련된 또 다른 RNN
(h(t) , yt는 y(t-1)와 입력 sequence의 요약 c에 대해 조건 지정)
t에서 decoder의 hidden state
ht=f(h(t-1), yt-1, c)
조건부 분포의 다음 symbol
P(yt│yt-1, yt-2, …, y1, c)=g(h(t), yt-1, c)
Encoder와 Decoder는 조건부 log-likelihood 최대화 하도록 공동 학습

θ: 모델 매개변수의 집합
(xn, yn): (입력 sequence, 출력 sequence)
앞의 내용을 그림으로 표현
Encoder의 각 step의 hidden state
h(t)=f(h(t-1), xt)
Decoder의 각 step의 hidden state
ht=f(h(t-1), yt-1, c)
source sentence가 나왔을 때 output sentence가 나올 확률 최대화
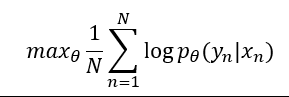
훈련된 모델의 사용법
input sequence가 주어졌을 때 target sequence 생성
input sequence와 target sequence 쌍의 점수 매기기
2.3 Hidden Unit that Adaptively Remembers and Forgets
계산과 구현에 더 단순한 은닉 단위 제안(GRU)
(hidden activation function)
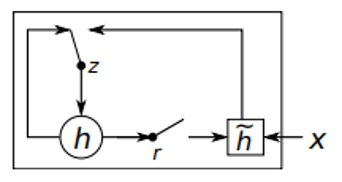
z(update gate): hidden state h를 새로운 hidden state h ̃로 업데이트 여부 선택
이전 hidden state에서 현재 hidden state로 얼마나 많은 정보 전달할지 제어
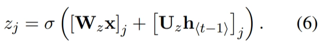
r(reset gate): 이전 hidden state를 무시할지 여부 결정
LSTM과 같이 sigmoid 함수를 통해 0~1 사이값
0에 가까워지면 hidden state는 이전 hidden state를 무시하고 현재 입력으로 리셋
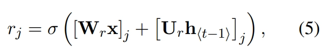
별도의 output gate가 없음
Long-term dependency 문제 극복
3. Statistical Machine Translation
논문은 해당 모델을 SMT 시스템에 적용
일반적으로 SMT에서 목표는 문장이 주어지면 아래 식을 maximize 하는 translation f를 구함
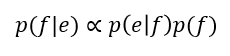
p(e│f): translation model
p(f): language model
실제 SMT는 feature와 weight가 있는 log-linear model로 계산
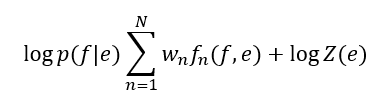
fn: n번째 특성
wn: n번째 가중치
Z(e): 정규화 상수
4. Experiments
Data: WMT-14
영어/불어 번역 작업으로 모델 학습, 평가
4.1 Data and Baseline System
Baseline model: Moses 오픈 소스 기계 번역 모델
RNN, CSLM(target language model), WP(word penalty)를 추가로 적용하여 실험
4.1.1 RNN Encoder-Decoder
1. Baseline
2. RNN
3. CSLM+RNN
4. Baseline+CSLM+RNN+WP
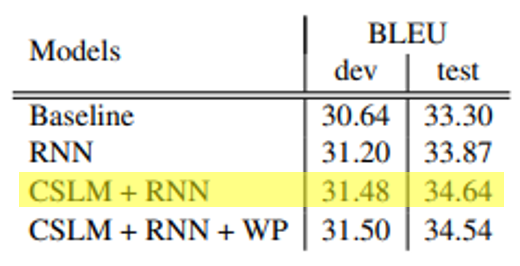
정량평가
성능이 향상된 것을 보임
CSLM+RNN이 가장 높은 성능을 보임
이는 CSLM과 RNN이 독립적으로 번역 시스템의 성능 향상에 기여했다고 판단

정성평가
모델이 학습한 phrase representation
해당 모델이 의미적, 문법적으로 더 잘 표현
'논문 > review' 카테고리의 다른 글
| Very Deep Convolutional Networks For Large-Scale Image Recognition (0) | 2024.07.03 |
|---|---|
| Attention Is All You Need 리뷰 (0) | 2024.06.22 |
| Forecasting LNG prices with the kernel vector autoregressive model 리뷰 (0) | 2022.08.05 |
| ImageNet Classification with Deep Convolutional Neural Networks 리뷰 (0) | 2022.07.22 |
| Fast Human Pose Estimation 리뷰 (0) | 2022.07.08 |



