
목차
0. Abstract
1. Introduction
2. The Dataset
3. The Architecture
3.1 ReLU Nonlinearlity
3.2 Training on Multiple GPUs
3.3 Local Response Normalization
3.4 Overlapping Pooling
3.5 Overall Architecture
4. Reducing Overfitting
4.1 Data Augmentation
4.2 Dropout
5. Details of learning
6. Results
6.1 Qualitative Evaluations
7. Discussion
0. Abstract
ImageNet ILSVRC-2010 120만개의 고해상도 이미지를 1000개의 다른 클래스로 분류
크고 깊은 합성곱 신경망 훈련
테스트 데이터 상위 1% error=37.5%, 상위 5% error=17.0% (이전에 비해 개선된 결과)
ILSVRC-2012에서 변형된 모델 사용
테스트 데이터 상위 5% error=15.2%
6천만개 매개변수, 650,000개의 뉴런이 있는 신경망(GPU환경)
convolution layer
max pooling layer
fully connected layer
1000-way softmax
(Dropout 사용)
1. Introduction
현재 객체 인식은 기계 학습 방법을 필수적으로 사용
최근까지 레이블이 지정된 이미지의 데이터 세트를 비교적 작았음
→ 간단한 인식 작업
하지만 현실적인 개체는 상당한 가변성을 나타냄
→ 개체 인식을 위해 더 큰 훈련 세트 필요
최근, 이미지로 레이블이 지정된 더 큰 데이터 세트 수집이 가능해짐
ex) LabelMe, ImageNet
수백만개의 이미지에서 수천개의 객체에 대해 배우려면 학습 능력이 큰 모델 필요
But 객체 인식 작업의 복잡성은 이 문제를 ImageNet과 같은 큰 데이터 세트로도 지정할 수 없다는 것 의미
→ 우리 모델도 가지고 있지 않은 모든 데이터를 위해 많은 사전 지식 필요
해결: CNN이 이러한 종류의 모델 중 하나를 구성
CNN
깊이와 너비를 변경하여 제어할 수 있음
이미지의 특징에 대해 강력하고 대부분 올바른 가정을 함
→ 연결과 매개변수가 훨씬 적어 훈련이 더 쉬움 but 가장 좋은 성능은 약간 떨어질 수 있음
문제: 여전히 엄청난 비용이 듦
해결: GPU 환경에서 훈련을 진행하면 용이
기여
- ILSVRC-2010, ILSVRC-2012 대회에서 사용된 ImageNet의 하위 집합에 대해 현재까지 가장 큰 convolution 신경망 중 하나를 훈련, 최고의 결과 달성
- 성능을 향상시키고 훈련 시간을 줄이는 여러 가지 새롭고 특이한 기능 포함
- 과적합 방지를 위해 효과적인 기술
최종 네트워크에는 5개의 convolution layer과 3개의 fully connected layer 포함(GPU환경에서 실행)
2. The Dataset
ImageNet
22,000개의 카테고리에 속하는 1,500만개 이상의 레이블이 된 고해상도 이미지 데이터 세트
ILSVRC
1000개의 카테고리에 각각 약 1,000개의 이미지가 있는 ImageNet의 하위집합
전체
Train data: 약 120만개
Validation data: 약 50,000개
Test data: 약 150,000개
일정한 입력 차원을 위해 256*256의 고정 해상도로 downsampling
상위 1개 및 상위 5개의 오류율
모델에서 가장 가능성이 높은 것으로 간주되는 1개 혹은 5개의 레이블 중 올바른 레이블이 아닌 테스트 이미지의 비율
3. The Architecture
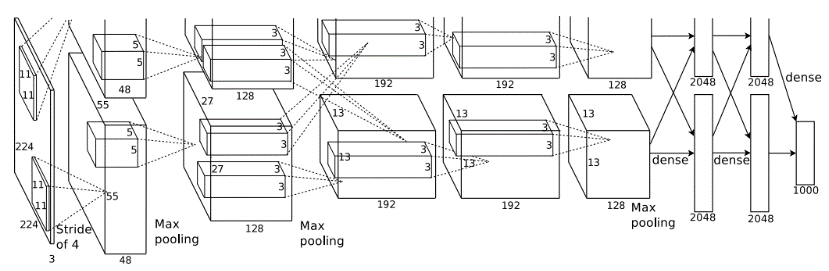
8개의 layer
- 5개의 convolution layer
- 3개의 fully connected layer
3.1 ReLU Nonlinearlity
tanh 단위를 사용하는 등가물보다 몇 배 더 빠르게 훈련
빠른 학습은 대규모 데이터 세트에서 훈련된 대규모 모델의 성능에 큰 영향을 미침
전통적인 포화 뉴런 모델을 사용하면 이 작업을 위해 그렇게 큰 신경망을 실험할 수 없었을 것
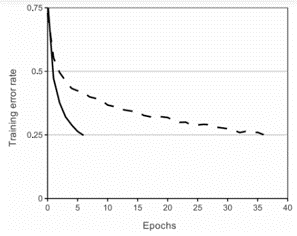
실선: ReLU가 있는 4-layer convolution 신경망
점선: tanh가 있는 동급 네트워크
3.2 Training on Multiple GPUs
단일 GTX 580 GPU에는 3GB의 메모리만 있어 훈련할 수 있는 네트워크의 최대 크기가 제한됨
→ 2개의 GPU에 네트워크를 퍼뜨림(병렬화 방식)
하나의 GPU에서 훈련된 각 convolution layer의 커널 수가 절반인 네트워크와 비교하여
상위 1% error 줄어듦, 상위 5% error 1.2% 줄어듦
3.3 Local Response Normalization
ReLU는 포화를 방지하기 위해 입력 정규화가 필요하지 않음
but 여전히 다른 로컬 정규화 방식이 일반화에 도움이 됨
(x, y) 위치에 커널 i를 적용한 다음 ReLU 비성형성을 적용하여 계산된 뉴런의 활용을 aix, y로 표시하면 응답 정규화 활용 bix, y는 다음 식으로 주어짐(N: layer의 총 커널 수, n: 인접한 커널 맵)
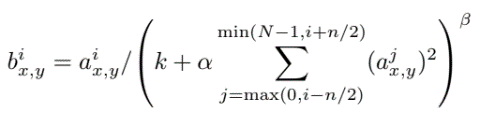
k=2, n=5, α=0.0001, β=0.75 사용
특정 레이어에 ReLU 비선형성을 적용한 후 이 정규화 진행
응답 정규화는 상위 1 error에서 1.4%, 상위 5 error에서 1.2% 감소
4-layer CNN은 정규화 없이 test error 13%, 정규화하면 test error 11%
3.4 Overlapping Pooling
CNN pooling layer
동일한 커널 맵에서 인접한 뉴런 그룹의 출력 요약
전통적으로 인접한 풀링 단위로 요약된 이웃은 겹치지 않음
s 픽셀 간격으로 떨어진 풀링 단위의 그리드로 구성되는 것
각각의 풀링 단위의 위치를 중심으로 하는 크기 z*z의 이웃 요약
- s=z로 설정하면 CNN에서 일반적으로 사용되는 로컬 풀링
- s<z로 설정하면 중첩 풀링 발생
중첩 풀링은 로컬 풀링과 비교하여 상위 1 error 0.4%, 상위 5 error 0.3% 감소
중첩 풀링이 있는 모델이 과적합하기 더 어려움
3.5 Overall Architecture
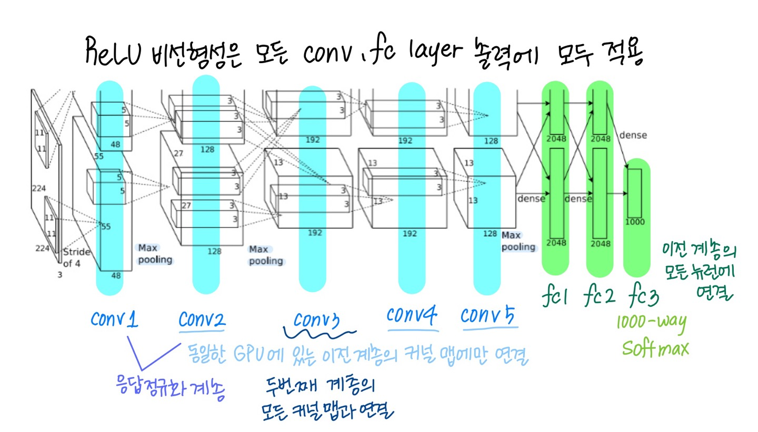
4. Reducing Overfitting
모델: 6천만개의 매개변수
문제: 제약 존재
→ 과적합 없이 매개변수를 학습하기에 적절하지 않음
과적합 방지를 위한 두 가지 방법
- Data Augmentation
- Dropout
4.1 Data Augmentation
이미지 데이터에 대한 과적합을 줄이는 가장 일반적인 방법: 레이블 보존 변환을 사용하여 데이터 세트를 인위적으로 확대
- 이미지 변환과 수평 반사 생성
256*256 이미지에서 임의의 224*224 패치 추출하고 훈련
→ 훈련 세트의 크기 2048배 증가
- RGB 채널의 강도 변환
각 훈련 이미지에 발견된 주성분의 배수 추가
→ 상위 1 error 1% 이상 감소
4.2 Dropout
확률 0.5로 각 hidden neuron의 출력을 0으로 설정하는 것
순방향, 역방향 전달에 기여하지 않음
→ 뉴런이 특정 다른 뉴런의 존재에 의존할 수 없기 때문에 뉴런의 복잡한 공동 적응을 감소시킴
→ 다른 뉴런의 다양한 무작위 하위 집합과 합께 유용한 더 강력한 기능을 학습해야 함
논문) 처음 두개의 FC에서 dropout 사용
5. Details of learning
stochastic gradient descent
batch_size=128
momentum=0.9
weight_decay=0.0005
가중치 업데이트 방법: 표준편차가 0.01인 0-mean gaussian distribution에서 각 레이어의 가중치 초기화
2, 4, 5 conv layer과 fc 계층에서 뉴런의 편향을 상수 1로 초기화
→ ReLU에 양수 입력을 제공하여 학습의 초기 단계 가속화
나머지 레이어에서 뉴런의 편향을 상수 0으로 초기화
모든 계층에 대한 동일한 학습률
휴리스틱 검증 오류율이 현재 학습률로 개선되지 않으면 학습률을 10으로 나눔
learning_rate=0.01
6. Results

ILSVRC-2010 결과
상위 1 test error=37.5%
상위 5 test error=17.0%
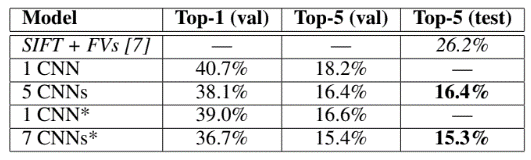
ILSVRC-2012 결과
상위 5 test error(mean)=16.4$
*: 사전 훈련 모델
6.1 Qualitative Evaluations

(왼쪽)
8개의 ILSVRC-2010 테스트 이미지와 모델에서 가장 가능성이 높은 것 5개의 레이블
(오른쪽)
첫 열: 5개의 ILSVRC 테스트 이미지
나머지 열: 테스트 이미지의 특징 벡터에서 가장 작은 유클리드 거리를 가진 마지막 은닉 레이어에서 특징 벡터를 생성하는 6개의 훈련 이미지
7. Discussion
궁극적으로 시간 구조가 정적 이미지에서 누락되거나 훨씬 덜 분명하지만 매우 유용한 정보를 제공하는 비디오 시퀀스에서 매우 크고 깊은 convolution network를 사용하길 바람
'논문 > review' 카테고리의 다른 글
| Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation 리뷰 (0) | 2022.08.19 |
|---|---|
| Forecasting LNG prices with the kernel vector autoregressive model 리뷰 (0) | 2022.08.05 |
| Fast Human Pose Estimation 리뷰 (0) | 2022.07.08 |
| Image-to-Image Translation with Conditional Adversarial Networks 리뷰 (0) | 2022.07.06 |
| Generative Adversarial Nets 리뷰 (0) | 2022.07.04 |



