
목차
0. Abstract
1. Introduction
2. Related Work
3. Fast human Pose Estimation
3.1 Compact Pose Network Architecture
3.2 Supervision Enhancement by Pose Distillation
3.3 Model Training and Deployment
4. Experiment
4.1 Experimental Setup
4.2 Comparisons to State-Of-The-Art Methods
4.3 Ablation Study
5. Conclusion
0. Abstract
기존 인간 포즈 추정 접근 방식
모델 일반화 성능을 개선하는 방법만 고려
심각한 효율성 문제는 고려하지 않음
문제: 실제 사용에서 확장성과 비용 효율성이 떨어지는 무거운 모델의 개발로 이어짐
논문) 위의 작업에서 연구되지는 않았지만, 실질적으로 중요한 포즈 모델 효율성 문제 조사
해결책
FPD(Fast Pose Distillation) 모델 학습 전략 제시
특히 FPD는 낮은 계산 비용으로 빠르게 실행할 수 있는 경량 포즈 신경망 아키텍쳐 훈련
자세 구조 지식을 효과적으로 전달
결과
MPII human pose와 Leeds Sports Pose 데이터셋에서 모델 비용 효율성 측면에서 광범위한 최첨단 포즈 추정 접근 방식에 비해 FPD의 장점을 보여줌
1. Introduction
인간 자세 추정은 CNN모델의 발전으로 함께 급속히 발전함
이유: 심층 신경망이 제약이 없는 인체 모양, 배경이 있는 경우에도 임의의 인물 이미지에서 관절 위치까지의 비선형적 매핑 기능을 근사하는데 강해서
문제: 모델의 깊이와 너비가 큰 리소스 집약적 네트워크를 훈련하고 배포하는 비용과 함께 제공되어 비효율적인 모델 추론이 발생
→ 스마트폰과 같은 제한된 장치에서 확장성이 좋지 않음
이전 해결방안: 모델 실행 속도 향상을 위해 네트워크 매개변수를 이진화하려 했지만 모델 일반화 능력이 취약해짐
논문: 모델 성능 저하 없이 포즈 추정 효율성을 개선하면서도 비슷한 정확도를 유지하는 문제를 고려
문제: 최첨단 인간 포즈 네트워크를 위한 기본 CNN이 계층당 채널 수가 많고 훈련하기 어려워 소규모 네트워크를 구축하는데 비용이 효율적이지 않음 ex) Hourglass
해결방안: Hourglass 네트워크의 경량 변형을 설계, 작은 포즈 네트워크보다 효과적인 훈련 방법 제안 (=FPD)
FPD는 동일한 수준의 인간 포즈 예측 성능에 동시에 도달하는 동시에 매우 작은 모델 크기로 훨씬 빠르고 비용 효율적인 모델 추론을 가능하게 함
논문의 기여
1. 높은 비용의 모델 추론 비용으로 정확도 성능만 향상시키는데 주로 초점을 맞춘 기존의 시도와 달리, 충분히 연구되지 않은 인간 포즈 모델 효율성 문제를 조사
기존의 딥 포즈 추정 방법을 실제 응용 프로그램으로 확장하기 위해 중요한 문제
2. 작은 인간 포즈 CNN 네트워크를 보다 효과적으로 훈련할 수 있는 FPD 모델 훈련 방법 제안
이는 객체 이미지 분류 심층 모델을 유도하는데 성공적으로 활용된 knowledge distillation 아이디어를 기반으로 함
제한된 계산 예산에서 최고의 모델 성능을 추구하는 것을 목표로 함
3. 만족스러운 정확도를 허용하는 충분한 학습 용량을 유지하면서 보다 비용 효율적인 포즈 추정 CNN 모델을 구성할 수 있는 경량 Hourglass 네트워크 설계
기존의 최첨단 포즈 CNN 아키텍쳐 설계의 중복 정도를 광범위하게 조사하여 달성함
평가를 위해 MPII human pose와 Leeds Sports Pose 데이터셋 사용
2. Related Work
Human Pose Estimation
이전 작업: 모델 추론 비용 문제를 크게 무시하여 복잡하고 계산 비용이 많이 드는 모델을 사용하여 포즈 추정 정확도 향상에만 집중
문제: 사용 가능한 컴퓨팅 예산이 매우 제한된 실제 응용 프로그램에서 확장성과 배포 가능성을 크게 제한
모델 향상을 위해 설계된 몇가지 작업
-Bulat&Tzimiropoulos
리소스가 제한된 플랫폼을 수용하기 위해 매개변수 이진화된 CNN 모델 구축
문제
극적인 성능 저하로 이어져 안정적인 활용에 만족하지 못함(높은 정확도를 얻기 힘듦)
새로운 알고리즘을 이용하지 않고 모델 효율성을 개선하기 위해 좋은 범용 사례 이용
모델 효율성과 효율성 간의 균형에 대한 정량적 평가를 제공하지 않음
논문: 결과 모델이 실제 적용 시나리오에서 더 유용하고 신뢰할 수 있도록 모델 성능 비율을 유지하는 조건에서 포즈 추정 효율성 문제를 체계적으로 연구
Knowledge Distillation
목적: 서로 다른 능력을 가진 서로 다른 신경망 사이의 정보 전송과 관련
ex) 잘 훈련된 대규모 네트워크를 성공적으로 사용하여 소규모 네트워크를 훈련시키는데 도움이 됨
이론적 근거: 클래스 확률, 특징 표현, 계층 간 흐름의 형태로 표현되는 교사 모델의 추가 감독을 활용하는 것
(이는 최근 대규모 분산 신경망의 모델 학습 프로세스를 가속화, 여러 계층 또는 여러 학습 상태 간에 지식 전달에 적용)
결과: 훈련하기 쉬운 큰 네트워크를 훈련하기 어려운 작은 네트워크로 증류하기 위해 이용
이전: 범주 수준의 판별 지식 이상으로 작동
논문: 조밀한 조인트 신뢰 맵의 더 풍부한 구조화된 정보 전송. 최신 무선 신호 기반 포즈 모델
(but 모델 효율성 문제보다 무선 센서를 사용하여 폐색 문제를 해결하는 것을 목표로 함)
3. Fast human Pose Estimation
Human Pose Estimation
목표: 주어진 이미지에서 인간 관절의 공간 좌표 예측
지도 학습으로 훈련
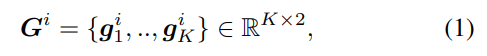
- 이미지 공간에 정의된 K관절로 레이블이 지정된 N명의 사람 이미지 훈련 데이터 세트 엑세스
- H: 이미지 높이, W: 이미지 너비 (픽셀)
- Loss Function으로 MSE기반 손실 함수 사용
실측 조인트 레이블을 나타내기 위해 레이블이 지정된 위치 주위에 가우스 커널을 중심으로 하여 각 단일 조인트에 대한 신뢰 맵 생성
(k번째 조인트 레이블에 대한 가우스 신뢰 맵 공식)
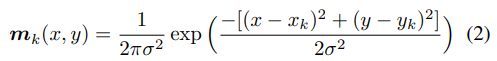
(x, y): 픽셀 위치 지정
σ: 미리 고정된 공간 분산(hyperparameter)
- MSE Loss Function
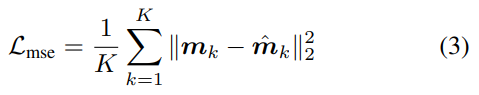
mk: k번째 관절에 대한 예측된 신뢰 맵
- SGD 알고리즘을 사용하여 미니 배치의 훈련 데이터에 대한 MSE 오류를 점진적으로 역전파하여 심층 CNN 포즈 모델 최적화
기존 포즈 방법: 추론 효율성을 무시하고 모델 성능을 최대화하기 위해 대규모 심층 신경망에 의존
논문: 경량 CNN 아키텍처를 설정하고 다음에 설명된 효과적인 모델 학습 전략을 제안하여 더 높은 확장성을 통해 제한을 해결
3.1 Compact Pose Network Architecture
인간포즈 CNN 모델은 일반적으로 동일한 구조를 가진 여러 반복 빌딩 블록으로 구성
이 중 Hourglass는 가장 일반적인 빌딩 블록 단위 중 하나
기존 설계: 전체 아키텍처에 많은 수의 채널과 블록을 배치
결과: 표현 능력과 계산 비용 사이의 최적이 아닌 절충안으로 이어져 비용 효율적이지 않음
Ex) 모든 레이어 내에 256개의 채널이 있는 9개의 잔여 블록이 있는 8개의 Hourglass 단계의 CNN 아키텍쳐 제안
더 빠른 모델 추론을 위해 기존 CNN 아키텍처의 비용을 최소화하고자 함
실험
MPII에서 95% 이상의 모델 일반화 용량을 달성하는데 절반의 단계(4개의 Hourglass module)가 충분함
레이어별 채널은 중복성이 매우 높아 절반(128)로 줄여도 성능이 1% 미만으로 저하
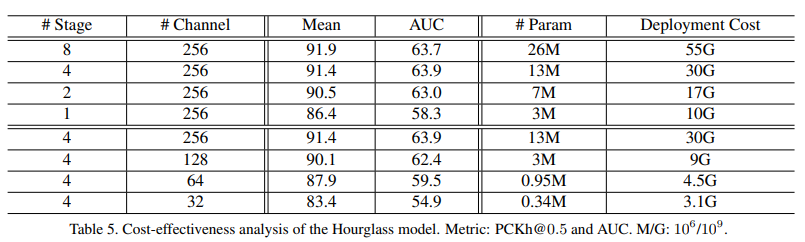
결과
원래 디자인의 1/6 계산 비용으로 포즈 추정을 위한 매우 가벼운 CNN 아키텍처를 구성
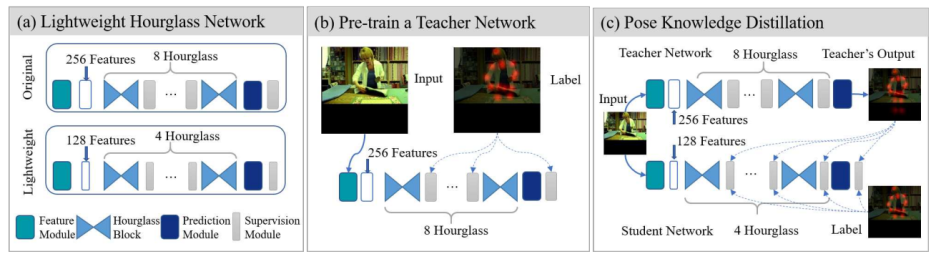
그림1. 제안된 Fast Pose Estimation 모델 학습 전략의 개요. 매우 비용 효율적인 인간 포즈 추정 모델ㅇ르 설정하려면
(a) 경량 Hourglass 네트워크와 같이 컴팩트 백본을 구축해야 함
소규모 타겟 니트워크를 보다 효과적으로 훈련하기 위해 포즈 추정 컨텍스트에서 knowledge distillation 원칙을 채택
(b) 포즈 추정 컨텍스트에서 knowledge distillation 원칙을 채택하기 위해 최첨단 Hourglass 네트워크 또는 기타 기존 대안과 같은 강력한 교사 포즈 모델을 사전 훈련함
(c) 교사 모델은 제안된 모방 손실 함수를 통해 포즈 knowledge distillation 절차에서 추가 감독 지침을 제공하는 데 사용됨
테스트 시 작은 대상 포즈 모델은 빠르고 비용 효율적인 배포를 가능하게 함
계산 비용이 많이 드는 교사 모델은 해당 식별 지식이 이미 대상 모델로 전송되어 배포에 사용되기 때문에 결국 페기됨

Remarks
저렴하고 빠르게 실행되는 작은 포즈 네트워크를 배치하는 것이 매력적이지만 이론적으로 얕은 네트워크가 깊은 네트워크의 유사 표현 능력을 갖고 있지만 경험적으로 이를 훈련시키는 것은 중요하지 않음
문제
대상 소규모 네트워크가 더 큰 교사 모델의 예측을 모방하도록 하는 객체 이미지 분류에서 유사한 문제 발생
밀집된 픽셀 공간에서 구조화된 인간 포즈 추정 처리에 얼마나 잘 작동하는지 불분명
다음에 설명할 Pose Distillation에서 답을 찾을 수 있음
3.2 Supervision Enhancement by Pose Distillation
Model pipeline
일반적인 knowledge distillation 전략 채택
1. 먼저 큰 교사 포즈 모델 훈련
실험) 기본적으로 깨끗한 디자인과 쉬운 모델 교육으로 인해 원래의 Hourglass 모델 선택
2. 교사 모델이 학습한 지식의 도움으로 대상 학생 모델 훈련
Knowledge distillation 발생
핵심: 교사의 지식을 효과적으로 추출하고 학생 모델의 교육으로 전달할 수 있는 적절한 모방 손실함수를 설계하는 것
이전 distillation 함수: 단일 레이블 기반 softmax교차 엔트로피 손실을 위해 설계
문제: 2D 이미지 공간에서 구조화된 포즈 지식 전송에 적합하지 않음
해결: 공식화된 공동 신뢰 맵 전용 포즈 증류 손실 함수 설계

- msk와 mtk 는 각각 사전 학습된 교사 모델과 학습중인 학생 대상 모델에 의해 에측된 k번째 관절에 대한 신뢰 맵
- 포즈 지도 학습 손실과의 비교 가능성을 최대화하기 위해 학생 모델과 교사 모델 간의 발산을 측정하기 위해 MSE 함수 선택
Overall Loss Function
훈련 중 자세 구조 knowledge distillation에 대한 전체 FPD 손실 함수
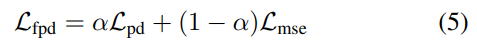
- α: 교차 검증에 의해 추정된 두 손실 항 사이의 균형 가중치
Lmse에 의해 훈련 샘플의 레이블된ground-truth 주석 예측
Lpd에 의해 더 강력한 교사 모델의 예측 구조와 일치하도록 학습
Further Remarks
제안된 포즈 distillation 손실 함수가 레이블이 지정된 데이터에 대해서만 훈련하는 것보다 일반화 가능한 대상 모델을 훈련하는 데 도움이 되는 이유? (포즈 추정의 맥락에서 설명 가능)
1. 수동 주석 프로세스에서 실제 위치를 찾기가 어려워 관절의 레이블이 잘못될 가능성
이 경우 교사 모델은 통계적 학습 및 추론을 통해 일부 오류 완화
잘못 레이블이 지정된 훈련 샘플의 오도 효과 줄일 수 있음
2. 혼란스러운 배경과 무작위 폐색 상황에 대한 사례
이 경우 교사 예측은 모델 추론으로 어려운 샘플을 설명하여 부드러운 학습 작업 제공 가능
3. 교사 모델은 원래 주석보다 더 완전한 관절 레이블을 제공할 수 있어 더 정확한 감독을 제공 + 누락된 관절 레이블의 오도 완화
4. 교사에 예측을 맞추는 것보다 실제 신뢰 맵을일치시키는 방법을 배우는 것이 더 어려울 수 있음
이는 교사 모델이 처리하기 어렵거나 쉬운 각 훈련 샘플에 대한 추론 불확실성을 퍼뜨렸기 때문
5. 교사의 신뢰 맵은 전체 훈련 데이터셋에서 학습된 추상적인 지식을 미리 인코딩하므로 knowledge distillation 도안 모든 개별 훈련 샘플을 학습할 때 고려하는 것이 유리할 수 있음
요약
제안된 모델은 잘못된 포즈 관절 주석을 처리할 수 있음
사전 훈련된 교사가 수동으로 잘못되었거나 레이블이 누락된 것보다 더 정확한 관절을 예측할 때 ground-truth 레이블과 교사 모델의 예측을 함께 사용함. 즉, 논문의 모델은 두 오류 중 하나에 대해 허용되지만 동시에 발생하는 오류는 발생하지 않는다
이는 모든 주어진 레이블을 맹목적으로 신뢰하는 기존 방법과 대조적으로 훈련 데이터에서 레이블 오류의 피해 완화
3.3 Model Training and Deployment
제안된 FPD 모델 훈련 방법
1. 기존의 MSE 손실에 의해 교사 포즈 모델을 훈련(식3)
2. 제안된 손실에 의해 대상 학생 모델을 훈련(식5)
교사 모델에서 목표 모델로의 knowledge distillation가 각 미니 배치 및 전체 교육 프로세스에서 수행
테스트 시간에 효율적이고 비용 효율적인 배포를 위해 작은 대상 모델만 사용하고 무거운 교사 네트워크는 버림
대상 모델은 이미 교사의 지식을 추출
4. Experiment
4.1 Experimental Setup
Dataset
MPII,LeedsSportsPose(LSP) 이용
MPII
다양한 인간 활동 및 이벤트가 포함된 YouTube 영상에서 수집
25k 장면 이미지, 40k 주석이 달린 인물 (훈련용 29k, 테스트용 11k)
각사람은 16개의 라벨이 붙은 신체 관절을 가짐
표준 train, validation, test 데이터 분할 채택
모델 검증을 위해 훈련 세트에서 3k 샘플 무작위 샘플링
LeedsSportsPose(LSP)
다양한 스포츠 장면의 자연인 이미지가 포함
확장 버전은 11k 훈련 샘플, 1k 테스트 샘플 제공
각 사람은 14개의 라벨이 붙은 신체 관절을 가짐
Performance Metrics
오류 임계값(τ)내에서 올바른예측의 비율을 정량화하는 표준 PCK(정확한 키포인트 백분율) 측정 사용
특히 양 τ는 몸통(LSP의 경우 0.2), 머리(MPII의 경우 0.5)의 크기에 대해 정규화
각각의 개별 관절을 각각 측정하고 그 평균을 전체 매트릭으로 사용
다른 τ값을 사용하여 PCK 곡선 산출
따라서 AUC는 다양한 결정 임계값에 대한 전체적인 측정으로 얻을 수 있음
훈련과 테스트에서 모델 효율성을 측정하기 위해 FLOP 사용
Training Detail
Torch에서 구현
제공된 위치와 크기에 따라 훈련 및 테스트 이미지 crop
Resize: 256*256
Randomscaling: 0.75~1.25
Rotating: ±30도
Horizontal flipping
RMSprop 최적화 알고리즘 채택
Learning rate: 2.5*10-4
Mini-batch size: 4
Epoch: 130(MPII), 70(LSP)
네트워크 아키텍처로 원래 Hourglass 교사 모델로 사용, 깊이와 너비가 더 적은 맞춤형 Hourglass를 대상 모델로 사용
4.2 Comparisons to State-Of-The-Art Methods
제안하는 FPD를 MPII와 LSP에 대한 최근 인간 자세 추정 기법과 광범위학 비교하여 평가
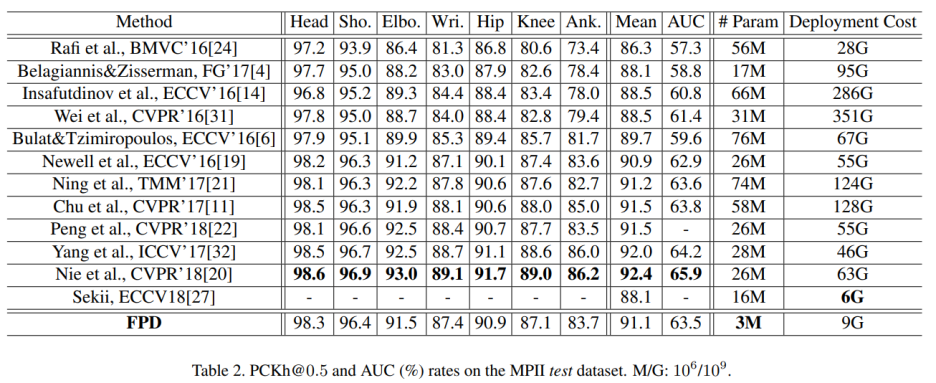
Result on MPII
제안된 FPD 모델은 상당히 효율적이고 저렴한 배포 비용 달성
모델 일반화 기능을 명확하기 손상시키지 않고 얻을 수 있음
최대 91.1% 달성
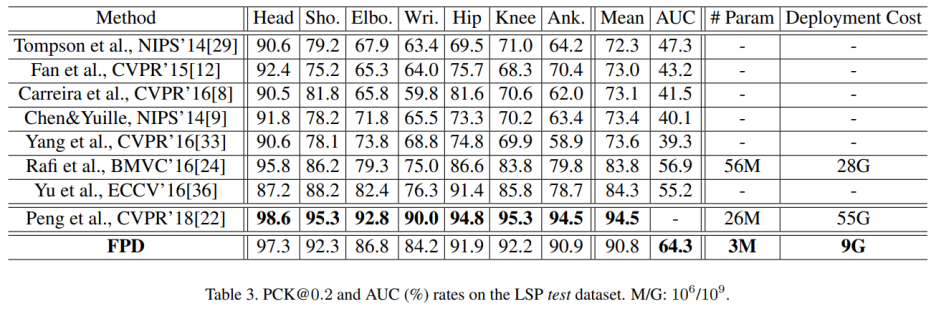
Result on LSP
MPII와 비교할 때 부분적으로 더 작은 크기의 훈련 데이터로 인해 딥러닝 모델에서 덜 평가됨
전반적으로 유사한 결과
Qualitative Examination
작은 FPD 모델은 다양한 배경, 인간 포즈 및 보기 조건이 있는 이미지에서 신뢰할 수 있고 강력한 포즈 추정을 여전히 달성함

4.3 Ablation Study
MPII 검증 세트에 대한 상세한 구성 요소 분석
FPD generalization evaluation
최첨단 Hourglass를 backbone 네트워크로 사용하는 것 외에 제안된 FPD 프레임워크에 통합될 때 최신 모델도 테스트
교사 모델로 원래 네트워크 채택, 학생 모델로 경량 변형을 구성
경량모델은 Hourglass 디자인을 기반으로 표1과 유사하게 구성
-단계수를 4로 줄임
-각 모듈의 채널 수 128
이 결과 비용 효율적인 포즈 추정 심층 모델을 생성하는 데 제안된 접근 방식의 우수한 일반화 기능을 제안
Cost-effectiveness analysis of Hourglass
비용 효율성 측면에서 최첨단 Hourglass 신경망 모델의 아키텍쳐 설계를 광범위하게 조사
테스트: 깊이(레이어 번호)와 너비(채널 번호)라는 두 가지 차원의 설계 테스트
결과: half stage(레이어)와 half 채널을 제거하면 성능 저하가 상당히 제한됨
= 원래 Hourglass 디자인이 비용 효율성이 낮고 중복성이 높다
이런 CNN 아키텍쳐 검사는 경량 포즈 CNN 아키텍쳐를 적절하게 공식화하는데 도움이 됨
Effect of pose knowledge distillation
가벼운 Hourglass 네트워크에서 포즈 지식 증류를 사용한 효과 테스트
다른 방법과 달리 모델 훈련에서 보조 데이터 세트 MPII의 이점을 추가로 얻음
이는 knowledge distillation의 일반 원리가 객체 범주화를 넘어 구조화된 포즈 추정 맥락에서 효과적임을 말함
Posedistillation loss function
포즈 knowledge distillation에 대한 손실 함수 선택의 효과 평가
테스트
교차 엔트로피 측정 기반 손실을 추가로 테스트
특히 모든 픽셀 신뢰 점수의 합이 1이 되도록 전체 신뢰 맵 정규화 (L1 정규화)
그 후 교차 엔트로피 기준을 사용하여 예측된 신뢰도 지도와 실제신뢰도 지도 간의 발산을 측정
결과: MSE가 교차 엔트로피보다 더 나은 선택임
Parameter analysis of loss balance
기존의 MSE 손실과 제안된 포즈 knowledge distillation 사이의 균형 중요성을 α로 평가
결과: α=0.5(동일한 중요도)일 때가 최적의 설정
문제: 이 매개변수 설정은 만족스러운 값의 넓은 범위에서 민감하지 않음
=교사 신호가 ground-truth레이블에서 멀지 않음을 의미
해결: 원래의 공동 신뢰 맵 레이블을 대체하는 대안적인 감독 제공 가능
5. Conclusion
새로운 FPD학습 전략 제시
목표: 기존 인간 포즈 추정 방법과 달리 실제로 대규모 배포로 확장하기 위해 연구되지 않고 실질적으로 중요한 모델 비용 효율성 품질을 해결하는 것을 목표로 함
방법: 경량 인간 포즈 CNN 아키텍쳐를 개발하고 대형 교사 모델에서 경량 학생 모델로 효과적인 포즈 구조 knowledge distillation 방법을 설계하여 가능함
결과: 네트워크 매개변수 이진화와 같은 기존 모델 압축 기술과 비교하여 정확도 성능 저하 없이 매우 효율적인 인간 포즈 모델 달성
실험: 두 개의 인간 포즈 데이터세트에 대해 광범위한 비교 평가 수행
결과: 광범위한 최첨단 대안 방법과 비교하여 FPD 접근 방식이 우월함
다른 실험 목표: 모델 비용 효율성의 이점에 대한 자세한 분석과 통찰력 제공을 위해
실험: 모델 구성 요소에 대한 일련의 절제 연구 수행
'논문 > review' 카테고리의 다른 글
| Forecasting LNG prices with the kernel vector autoregressive model 리뷰 (0) | 2022.08.05 |
|---|---|
| ImageNet Classification with Deep Convolutional Neural Networks 리뷰 (0) | 2022.07.22 |
| Image-to-Image Translation with Conditional Adversarial Networks 리뷰 (0) | 2022.07.06 |
| Generative Adversarial Nets 리뷰 (0) | 2022.07.04 |
| Conditional Generative Adversarial Nets 리뷰 (0) | 2022.06.24 |



