
목차
0. Abstract
1. Introduction
2. Related work
3. Adversarial nets
4. Theoretical Results
4.1 global optimality of pg=pdata
4.2 Convergence of Algorithm 1
5. Experiments
6. Advantages and disadvantages
7. Conclusions and future work
0. Abstract
Adversarial 과정을 통해 생성모델을 평가하는 새로운 프레임워크를 제안
두 개의 분리된 모델을 동시에 학습
- Generative model G(생성기): 데이터의 분포를 학습하는 모델
- Discriminative model D(판별기): 샘플이 G에서 온게 아니고 실제 훈련 데이터로부터 왔을 것이라는 확률 추정 모델
G는 D가 잘못된 결정을 할 확률 최대화
이 프레임워크를 “minimax tow-player game”이라 할 수 있음
논문) 임의의 G, D의 공간에서 G가 훈련 데이터 분포를 잘 복구하고, D가 G로부터 생성된 가짜 데이터와 진짜 데이터를 구분하지 못해 1/2이 되는 솔루션이 있다고 주장
G와 D가 multi layer perceptron으로 정의되면 전체 시스템은 backpropagation으로 학습
1. Introduction
딥러닝으로 우리는 다양한 종류의 데이터에 대한 확분포를 표현하고 모델을 발견할 수 있었음
지금까지 딥러닝에서 가장 성공적인 부분은 판별 모델이었음
(역전파, 드롭아웃, 구간별 선형활성화 유닛 기반)
문제
- 심층 생성모델은 생성모델의 목적 달성을 위한 최대 가능도 추정에 다루기 힘든 확률적 계산 근사하는 것
- 구간별 선형활성화유닛의 이점을 이용하는 데에 어려움이 있음
논문: 문제 해결을 위해 새로운 생성모델 추정 절차를 주장
Adversarial nets
G는 D를 속이도록 학습
D는 어떤 샘플이 G가 모델링한 분포로부터 나온 것인지 실제 데이터 분포로부터 나온 것인지 결정하는 것을 학습
이런 경쟁은 G와 D가 모두 목적을 달성할 때까지 학습
논문) 해당 프레임워크를 이용한 하나의 케이스로 G와 D 모두 multi layer perceptron으로 구성
3. Adversarial nets
G의 분포(pg)를 x에 대해 학습하기 위해 노이즈에 대한 사전분포 pz(z) 정의
노이즈 변수의 데이터 공간에서 매핑하는 MLP 정의(G(Z; θg))
이때 G는 파라미터 θg를 가진 미분가능 MLP
확률값을 출력하는 다른 MLP 정의(D(X; θd))
이때 D(x)는 pg가 아닌 실제 데이터로부터 얻어졌을 확률 계산
D가 실제 데이터와 G에서 온 샘플에 대해 올바른 라벨을 할당하는 확률을 최대화하도록 D 학습
동시에, G가 log(1-D(G(z)))를 최소화하도록 학습
= D와 G의 minimax game
목적함수
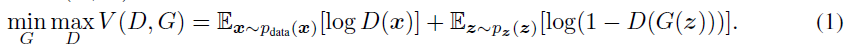
문제: 훈련 내부 루프에서 완료까지 D를 최적화하는 것은 계산적으로 금지, 유한 데이터 세트에서 과적합 발생 가능
논문: D를 최적화 k 단계와 G를 최적화 한 단계를 번갈아 진행
결과: G가 충분히 천천히 변하면 D는 최적 솔루션 근처에서 유지
실제 문제 발생 가능
문제: GAN을 학습하다 보면 G가 잘 학습하기에 충분한 gradient가 없을 수 있음
(발생 이유: 학습 초기 G가 생성하는 데이터가 D의 훈련 데이터와 분명히 달라서 높은 신뢰도로 샘플 거부하므로)
→ log(1-D(G(z)))가 saturate 됨
해결: log(1-D(G(z)))를 최소화하기 위해 G를 훈련하는 대신 log(D(G(z)))를 최대화하는 방향으로 훈련
결과: 학습 초기에 강한 gradient 제공
Adversarial nets의 학습 과정
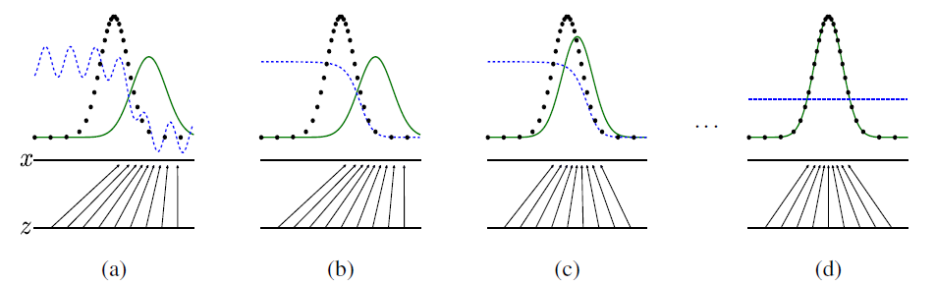
검정 점선: 데이터 생성 분포(px)
녹색 실선: 생성모델(pg)
파란 파선: 구별모델(D)
하단 수평선: z가 동등하게 sample을 뽑고 있는 도메인
상단 수평선: x의 도메인
화살표: x=G(z)가 변형된 샘플에 pg가 non-uniform
(a)→(b)→(c)→(d)로 진행
(a): D는 부분적으로 정확히 분류
(b): D의 내부 루프에서는 샘플을 구별하기 위해 훈련
(c): G의 업데이트 이후, G(z)가 더욱 원본으로 분류될 것처럼 D의 기울기 조정
(d): G와 D가 충분한 능력을 가질 때까지 학습한 후, pg=pdata가 되는 지점에 도달하여 더 이상 성능이 향상되지 않음
(D=1/2가 되어 D는 더 이상 구분하지 못함)
4. Theoretical Results
G는 z~pz일 때 얻는 샘플들의 확률분포 G(z)로 pg를 암묵적으로 정의
충분한 데이터와 시간이라면 아래 알고리즘이 pdata의 좋은 추정치로 수렴되길 바람

1 epoch 마다 아래를 반복
아래를 k번 반복(논문에서는 k=1로 적용)
pg(z)로부터 m개의 노이즈 샘플링
pdata(z)로부터 m개의 노이즈 샘플링
Ascending stochastic gradient로 V(G, D)를 최대화하도록 D를 업데이트
이후
pg(z)로부터 m개의 노이즈 샘플링
Descending stochastic gradient로 V(G, D)에서 log(1-D(G(z)))를 최소화하도록 G를 업데이트
Momentum을 이용한 optimizer 이용
4.1에서는 minimax game이 pg=pdata에 대한 전역 최적값임을 보임
4.2에서는 알고리즘1이 식1을 최적화하여 원하는 결과를 얻음을 보임
4.1 global optimality of pg=pdata
모든 가능한 G에 대한 최적의 D 구하기
optimal한 D는 아래와 같이 나옴(그러므로 알고리즘 1은 수렴)

증명) 어떤 주어진 G에 대해 D는 V(G, D)를 최대화
(D(x)에 대해 편미분하고 결과값을 0으로 하여 계산)
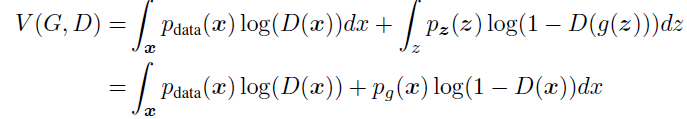
(a, b)∈R2/{0, 0}에서 y→alog(y)+blog(1-y)는 a/(a+b)로 [0, 1]에서 최대치
D는 Supp(pdata)∪Supp(pg)밖에서 정의될 필요 없음
증명 끝
최적의 D를 원래의 목적함수 식에 대입하여 C(G)유도
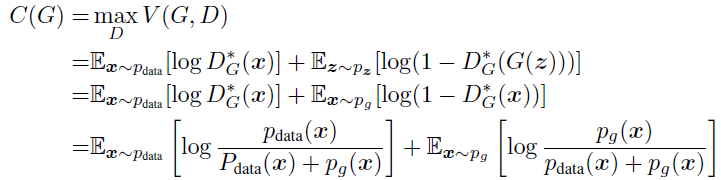
4.2 Convergence of Algorithm 1
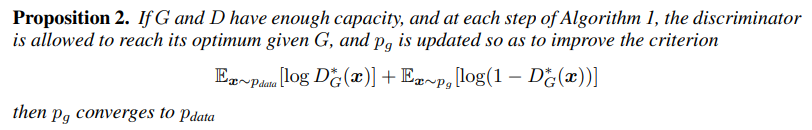
G와 D가 충분한 capacity를 가지며 알고리즘1의 각 스텝에서 D가 주어진 G에 대해 최적점에 도달 가능
동시에 pg는 pdata에 수렴
MLP의 성능은 이론적으로 보장될 수 없는데도 사용하기에 합리적인 모델
5. Experiments
데이터셋: MNIST, TFD, CIFAR-10
G
Activation function: rectifier, linear, sigmoid
노이즈를 G의 맨 아래 레이어에서 입력으로만 사용
D
Activation function: maxout
Dropout
G로 생성된 샘플에 Gaussian Parzen window를 fitting
해당 분포에서 log-likelihood를 확인해 pg test set의 확률 추정
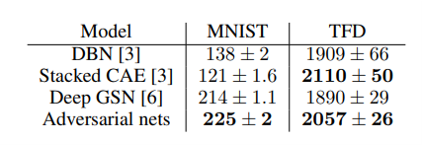
Parzen window기반 log-likelihood 추정
MNIST: test data’s log-likelihood average ± 오차평균
TFD: k-fold validation의 각 fold에 대한 log-likelihood’s average

G에 의해 생성된 샘플 시각화
(a) MNIST
(b) TFD
(c) CIFAR-10 (fully connected model)
(d) CIFAR-10 (convolutional D and deconvolutional G)
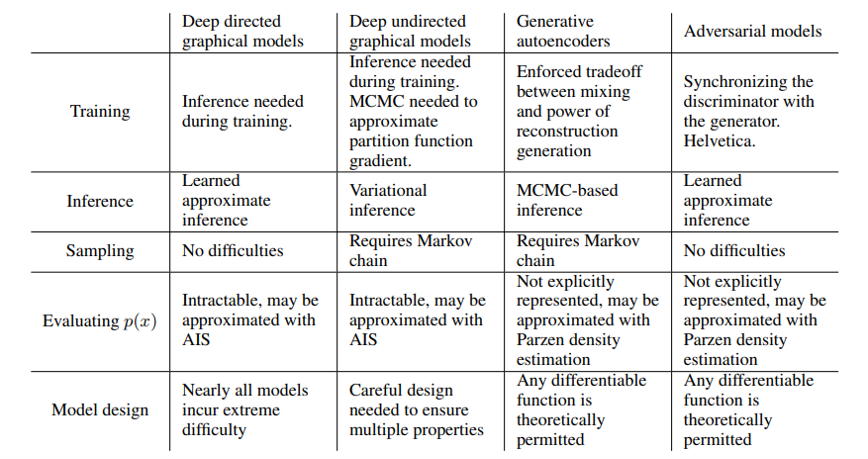
Deep generative modeling에서 발생하는 다양한 어려움
6. Advantages and disadvantages
단점
pg (x)의 명시적 표현이 없음
훈련 중 D를 G의 균형을 잘 맞춰야 함
장점
Markov chain 불필요
학습 단계에서 inference 필요 없음
다양한 기능의 모델 통합 가능
직접 업데이트 되지 않고 D의 기울기 조정만으로 G의 통계적 이점을 얻을 수 있음
Sharp한 표현을 얻음
7. Conclusions and future work
1. c를 G, D에 모두 추가하는 것으로 CGAN p(x|c)를얻음
2. 주어진 x에서 z를 예측하는 보조 네트워크를 훈련시켜 학습된 근사추론 진행 가능
3. Parameter를 공유하는 조건부 모델들의 집합을 훈련시켜 모든 조건부확률을 훈련시켜 근사적으로 모델링 가능
4. Semi-supervised learning: D, inference net의 feature들은 제한된 레이블 데이터셋에서 분류기의 성능 향상 가능
5. 효율성 개선: 훈련 중 G, D의 조정을 위해 더 좋은 방법 고안, 훈련 동안 z표본 추출을 위해 더 나은 분포를 결정하여 학습 가속화
'논문 > review' 카테고리의 다른 글
| Forecasting LNG prices with the kernel vector autoregressive model 리뷰 (0) | 2022.08.05 |
|---|---|
| ImageNet Classification with Deep Convolutional Neural Networks 리뷰 (0) | 2022.07.22 |
| Fast Human Pose Estimation 리뷰 (0) | 2022.07.08 |
| Image-to-Image Translation with Conditional Adversarial Networks 리뷰 (0) | 2022.07.06 |
| Conditional Generative Adversarial Nets 리뷰 (0) | 2022.06.24 |



