
목차
0. Abstract
1. Introduction
2. ConvNet Configuration
2.1 Architecture
2.2 Configuration
2.3 Discussion
3. Classification Framework
3.1 Training
3.2 Testing
3.3 Implementation Details
4 Classification Experiments
4.1 Single Scale Evaluation
4.2 Multi-Scale Evaluation
4.3 Multi-Crop Evaluation
4.4 ConvNet Fusion
4.5 Comparison with the state of art
5. Conclusion
0. Abstract
대규모 이미지 인식에서 convolution network 깊이에 따른 정확도
“ConvNet” -> Convolutional Networks
매우 작은 (3*3) convolution filter를 이용해서 깊이 증가
prior-art에서 엄청난 발전
16~19 weight layer 깊이에서 이루어짐
1. Introduction
대규모 이미지, 영상에서 ConvNet은 엄청난 성공 -> GPU, 큰 공공의 이미지 레포지토리 존재(ImageNet)
ImageNet Large-Scale Visual Recognition Challenge에서 deep visual recognition architecture의 중요한 역할이 진행됨
(고차원 shallow feature encoding에서부터 deep ConvNet까지)
computer vision 분야에서 ConvNet이 더 상품화되면서,
더 높은 정확성 달성을 위한 많은 시도가 이루어짐
ex1) small receptive window size & first convolutional layer에 더 작은 stride
ex2) 전체 이미지와 다양한 스케일의 빽빽한 train & test network
ex3) 이 논문에서는 깊이(depth)를 다르게 함
- architecture의 parameter 수정
- 꾸준히 network의 깊이 증가(convolution layer추가)
- 모든 layer의 매우 작은 3 * 3 convolution filter을 사용하면서
-> 더 높은 정확도를 보임
2. ConvNet Configuration
공평한 환경에서 ConvNet 깊이 증가에 따른 발전을 측정하기 위해, 모든 ConvNet layer 배치는 같은 원리를 사용
2.1 Architecture
training 중 ConvNet 입력은 224 * 224 RGB 이미지로 고정.
각 픽셀의 RGB값의 평균을 빼는 전처리 진행

+ 배치 중 1개에 (1 * 1) Conv. filter 이용하여 입력 channels의 선형 변형
- Conv. stride = 1 pixel로 고정
- Conv. layer 입력의 공간 padding은 convolution 이후에 공간 해결책을 보존하는 3 * 3 Conv. layer의 1 pixel padding
- 공간 pooling은 몇몇개의 Conv. layer 이후에 5개의 max-pooling layer로 실행
(max-pooling은 2 * 2 pixel window, stride = 2)
- 3개의 FC layer (모든 network에서 동일하게 진행)
처음 2개는 4096개의 channel
다음 1개는 1000 channels (분류 1000개 이므로) + softmax layer
- 모든 hidden layer은 비선형을 조정하는 것으로 구성되어 있음(ReLU)
- Local Response Normalization (LRN)은 적용하지 않음
이유: 성능이 더 나아지지 않고 메모리, 시간만 더 사용하므로
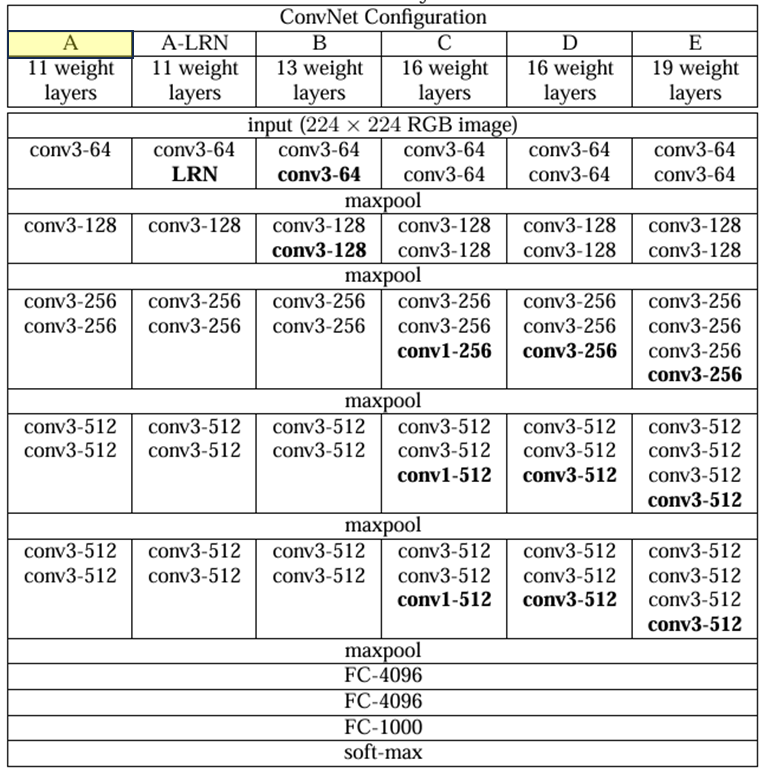
2.2 Configuration
깊이에서만 차이
너비는 처음에 제일 작고(64) max-pooling layer이후 2배씩 하여 512까지
깊이가 깊어도 얕은 것보다 그렇게 parameter 개수가 크지 않음
2.3 Discussion
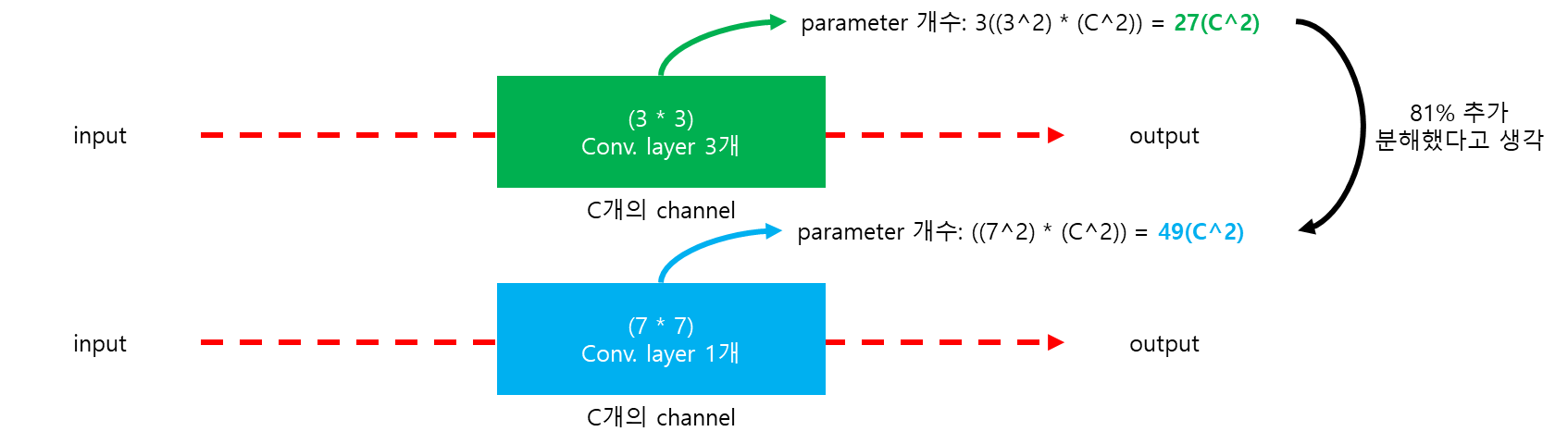
처음 Conv. layer에 큰 것을 받는 대신 전체 네트워크에 매우 작은 3 * 3을 받음
stride = 1로 모든 픽셀을 빙빙 돌림
Q. 그럼 7 * 7을 사용하는 것 보다 뭐가 좋음?
A1. 1개 대신 3개의 비선형 조정 레이어를 포함
결정 함수에 더 차별점이 있음
A2. parameter 개수 감소

3. Classification Framework
3.1 Training
Conv. Net 트레이닝 과정은 multi-nomial logistic regression 목표를 momentum을 이용한 역전파 기반 mini-batch gradient descent으로 최적화합니다.
- batch-size = 256
- momentum = 0.9
- 정규화로 weight 감수 (L2정규화 penalty multiplier = 5 * (10^(-4))
- 처음 2개의 FC layer에 Dropout (ratio = 0.5)
- learning rate = 10^(-2)
(validation set 정확도가 나아지지 않으면 10 감소)
결과 learning rate가 3번 감소됨
370k 반복, 74 epoch에서 멈춤
더 많은 매개변수와, 더 깊은 네트워크여도 수렴하기까지 시간이 더 적음
- 더 큰 깊이와 더 작은 conv. filter에 의해 부과된 암시적 정규화
- 특정 레이어 사전 초기화
network 가중치의 초기화는 중요함!!
틀리게 하면 깊은 network에서 learning gradient의 안정성이 좌우됨
이를 해결하기 위해 A model로 학습 시작
- 처음 4개 layer, 3개 FC layer 초기화
- 중간 random 하게 초기화
- 가볍게 train
- learning rate를 줄이지 않아 learning 중 변하도록 구성
- random 초기화를 위해 weigh를 정규분포 ~N(0, 10^(-2))에서 sampling
- bias = 0으로 초기화
pre-training없이 가중치 초기화 가능
A model로 학습한 후 더 깊은 architecture에 학습
Training image size
input = 224 * 224
training scale S 설정 방법
1. S 고정
single scale training에 대응
실험에서 model training 평가를 2개의 고정 스케일로 진행
- S = 256
- S = 384 (속도를 높이기 위해 초기화로 S = 256 사전 학습 후 더 작은 learning rate = 10^(-3) 이용)
2. S를 multi-scale training으로 진행
각 training 이미지가 randomly sampling된 S[S_min = 256, S_max = 512]에 독립적으로 rescale된 상태 (무작위 선택)
이미지 속 object가 다른 사이즈일 수 있으므로 training 안에 들어가는 것이 좋음 (더 넓은 범위 스케일로 학습 가능, 다양한 크기에 대한 대응 가능)
(S = 384로 고정하여 사전학습한 후) S를 무작위로 선택해가며 fine-tuning 진행 “scale jitter”
rescale이미지에서 랜덤하게 crop > random RGB 색 변경
3.2 Testing
사전 정의된 가장 작은 이미지로 rescale된 후 test scale “Q”라고 나타낸다.
(Q는 train scale S와 동일할 필요는 없다)
network는 rescale된 test image에 적용한다.
FC layer들이 먼저 conv. layer로 변환한다. (이때 uncrop된 전체 이미지 적용한다.)
- 1FC 7 * 7 conv layer
- 2FC 1 * 1 conv layer
- 3FC 1 * 1 conv layer
결과: class score map (channel 개수 = class 개수)
horizontal flip으로 test data augmentation
test에는 sample에 multi-crop을 적용할 필요 없음
multi-crop evaluation은 dense evaluation과 상보적
이 논문에서는 비교를 위해 multi-crop 예제도 진행
50 crops
3 scale로 총 150 crops
4 scale로 총 144 crops
3.3 Implementation Details
4 Classification Experiments
Dataset
ILSVRC – 2012 dataset
1000 classes의 이미지 보유 (train 1.3M, valid 50K, test 100K)
평가 방법: top 1 error, top 5 error
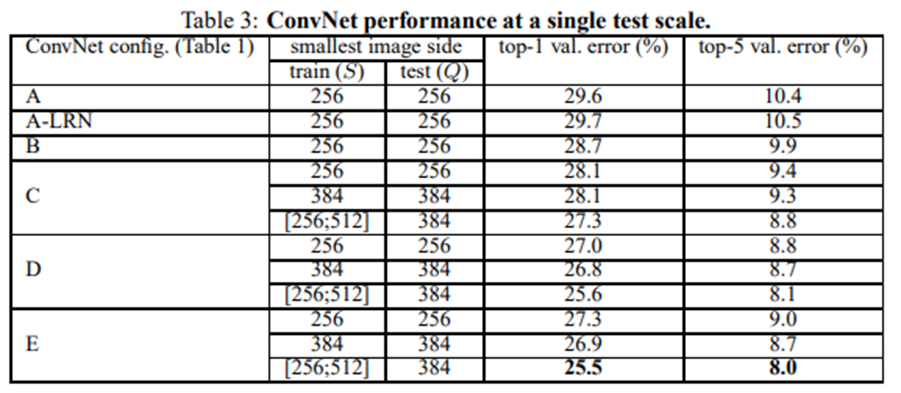
4.1 Single Scale Evaluation
test image size Q = S
Q = 0.5 * (S_min + S_max), S ∈ [S_min, S_max]
1. LRN을 적용해도 더 나아지지 않음
2. (3 * 3) 작은 필터의 깊은 모델이 (5 * 5) 큰 필터의 얕은 모델보다 더 좋음
3. S = 256, S = 384 고정된 것보다 S ∈ [256, 512]로 선택하는 것이 더 좋음
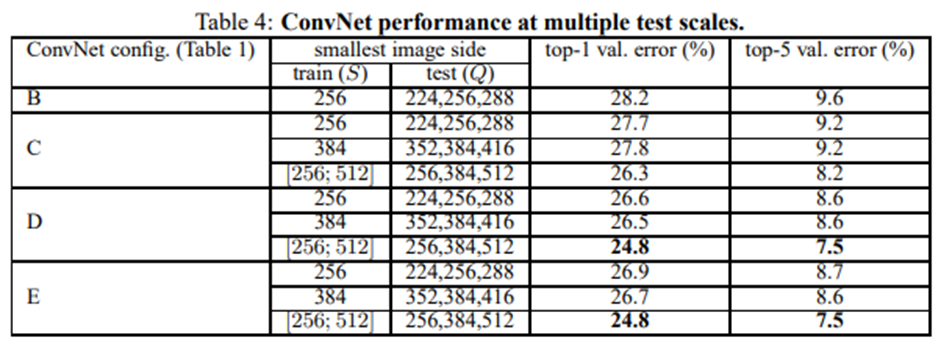
4.2 Multi-Scale Evaluation
S가 고정된 경우 Q = {S - 32, S + 32}
학습에 scale jitter 적용한 경우 Q = {S_min, 0.5 * (S_min, S_max), S_max},
S ∈ [S_min, S_max]
1. scale jittering의 결과가 더 좋음
2. 깊은 것이 더 좋음
4.3 Multi-Crop Evaluation
dense Conv. net과 multi-crop evaluation 비교
multi-crop이 조금 더 좋은 편
서로 보충관계이므로 섞는 것이 가장 좋음

4.4 ConvNet Fusion
모델 몇몇개 합쳐보기

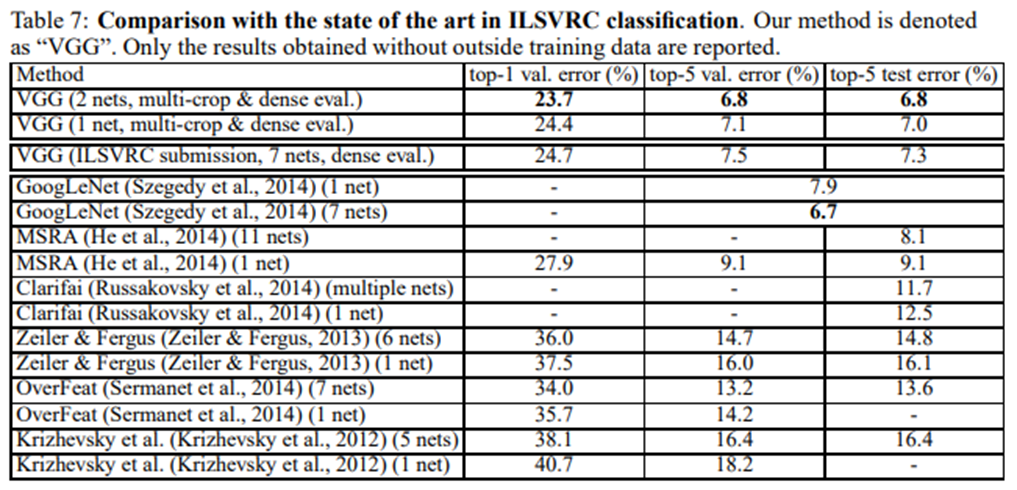
4.5 Comparison with the state of art
5. Conclusion
VGG 16 weight layers (Model D)




