
목차
0. Abstract
1. Introduction
2. Related Work
2.1 Unsupervised Feature-based Approaches
2.2 Unsupervised Fine-tuning Approaches
2.3 Transfer Learning from Supervised Data
3. BERT
3.1 Pre-training BERT
3.2 Fine-tuning BERT
4 Experiments
4.1 GLUE
4.2 SQuAD v1.1
4.3 SQuAD v2.0
4.4 SWAG
5. Ablation Studies
5.1 Effect of Pre-training Tasks
5.2 Effect of Model Size
5.3 Feature-based Approaches with BERT
6. Conclusion
0. Abstract
BERT: “Bidirectional Encoder Representations from Transformer”
이전과 다르게 모든 layer의 오른쪽, 왼쪽 텍스트를 고려
레이블링되지 않은 언어에 pre-train deep bidirectional representations
pre-trained BERT model은 하나의 추가 output layer로 fine-tuned됨 -> 상당한 구조의 수정 없이 다양한 작업
(QA, 언어추론)의 SOTA가 되기 위해 경험적으로 강하고 개념적으로 간단한 방법으로 SOTA 달성
1. Introduction
언어 모델 pre-training은 자연어 처리 발전에 효과적으로 보여짐
ex1) 자연어추론(문장 수준), 문단 > 문장 사이 관계 예측에 도움이 됨
ex2) token level의 결과 > 전체적으로 분석하고 token 단위로도 분석

최신 기술이 pre-train representation 중 특히 fine-tuning의 힘을 제한하는데,
주요 제한: standard language models가 unbidirectional함 > pre-training 중에 사용되는 아키텍쳐 선택이 제한됨
OpenAI GPT에서 left-to-right architecture 이용
모든 token이 이전 token의 transformer의 self-attention layers에 포함
> sentence level에 선택적, token level의 fine-tuning approach에 위험
ex) QA > 양방향에 포함된 문자가 중요함
논문: fine-tuning approach의 발전: BERT
pre-train의 목표로, 이전처럼 양방향이 아닌 제한을 완화 by.masked language model (MLM)
MLM: input의 몇몇 토큰을 random하게 mask하여 문맥을 이용해서 가려진 기존의 글자를 예측
left-to-right language model pre-training과 다르게, MLM은 next sentence prediction에 사용
(text-pair representation을 pre-train)
기여
- language representation에 bidirectional pre-training의 중요성
- pre-trained representations가 많은 무겁게 엔지니어링된 필요를 줄임
- SOTA
2. Related Work
2.1 Unsupervised Feature-based Approaches
2.2 Unsupervised Fine-tuning Approaches
2.3 Transfer Learning from Supervised Data
3. BERT


Model Architecture
“BERT” : multi-layer bidirectional transformer encoder (“Annoted Transformer”)
- L: number of layers (Transformer block)
- H: hidden size
- A: self-attention head 개수

- Open AI GPT: 왼쪽 token만 사용 가능, 제한된 self-attention 사용
- BERT: bidirectional

Input/Output Representations
BERT의 차후를 다양하게 다루기 위해
input representation single sentence, sentence pair 을 하나의 token sequence로 대표
sentence가 실제 언어 문장보다 임의적인 인접한 text가 됨
sentence는 single sentence이든 sentence pair이든 BERT의 input sequence가 됨
word piece embedding을 이용 (30,000 token 단어)
모든 sequence의 첫 token은 special classification token ([CLS])임
마지막 hidden state는 분류의 총합인 [CLS]에 대응
> token sequence의 결합된 의미를 가지게 됨 (분류가 아닌 경우 토큰 무시)

- E: embedding
- [CLS] token의 마지막 hidden vector은 𝐶∈𝑅^𝐻
- 𝑖^𝑡ℎ input token의 마지막 hidden vector을 𝑇_𝑖∈𝑅^𝐻
주어진 token에서 input은 대응되는 token, segment, position embedding의 합으로 구성

self-attention을 사용하는 Transformer에서 encoder부분을 사용하는데,
self-attention은 입력의 위치에 대해 고려하지 않음
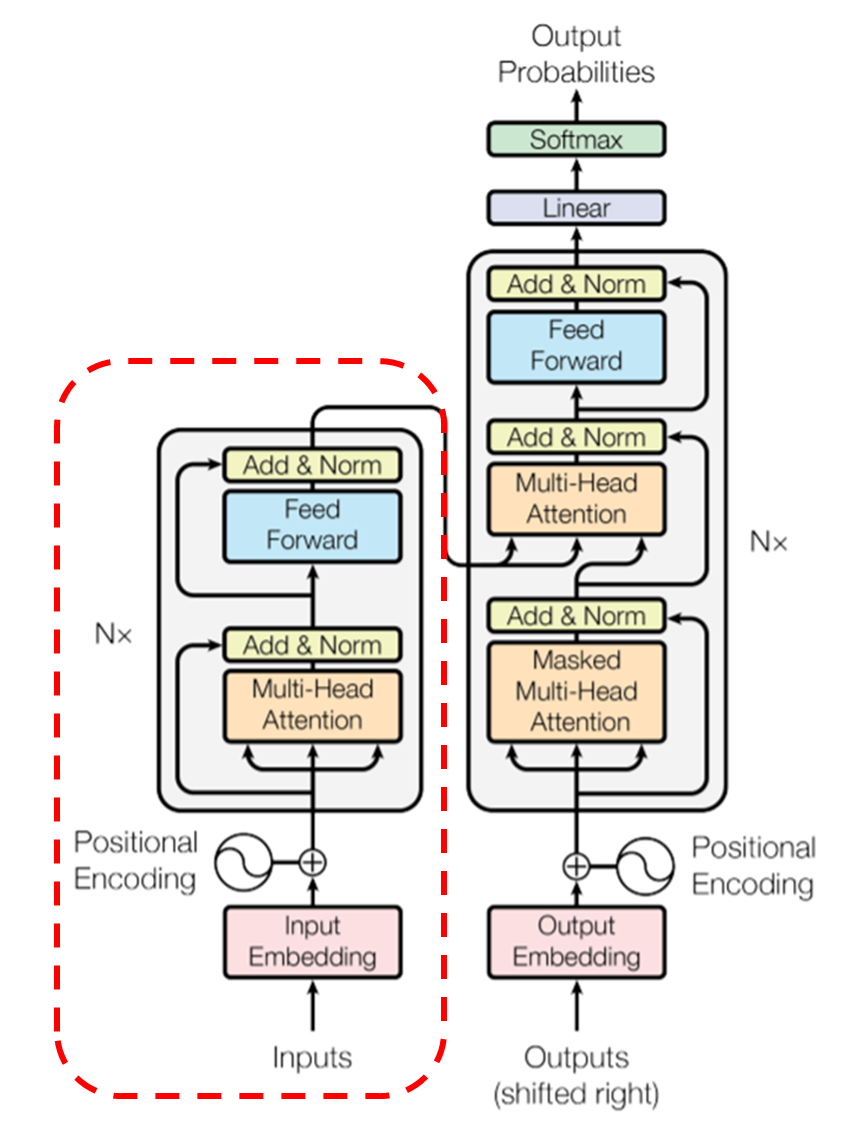
Transformer의 encoder 이용
3.1 Pre-training BERT
기존 left-to-right, right-to-left model 사용 X

Task#1: Masked LM

기존 조건: language model: left-to-right, right-to-left
이유: bidirectional 조건화는 각 단어가 간접적으로 “자기자신을 볼 수 있도록”하는 모델이 되어
> 모델이 multi-layer 맥락에서 대상 단어를 간단히 예측 가능하기 때문에

> deep bidirectional representation 학습하기 위해,
input token을 랜덤하게 몇 %를 단순히 마스킹함 > 그리고 그 마스킹 된 토큰을 예측함 > “masked LM (MLM)”
(=문학에서는 cloze task라고 함)
이 경우 mask token에 대응하는 최종 hidden vector는 단어의 출력 softmax에 공급 (= standard LM)
논문: each sequence에 random하게 wordpiece token의 15% mask
전체 input을 구성하기보다는 masked 단어를 예측
이런 방법으로 bidirectional pre-trained model을 가질 수 있지만, > pre-training과 fine-tuning 사이 mismatch 발생 가능
이유: [MASK] token이 fine-tuning에서 나타나지 않으므로
해결방법: masked word를 늘 실제 [MASK] token으로 대체하지 않음
training data generator는 random하게 15%의 token 위치를 예측하기 위해 선택
if) i번쨰 token 선택, i번째 token을
(1) 80%) [MASK] token으로 대체
(2) 10%) random token으로 대체
(3) 10%) 바꾸지 않음
그리고 T_i가 cross entropy loss를 사용해 기존 token 예측
Task#2: Next Sentence Prediction (NSP)
추후 작업 중 중요한 question & answering 이나 natural language inference (NLI)은 두 문장 관계에 대한 이해의 기반



pre-trained된 transfer learning 하여 실제 NLP task 과정

일반 모델: 데이터 > ML > 분류
BERT: 대량 corpus > BERT > data > ML > 분류
대량의 코퍼스를 Encoder가 임베딩하고 (언어 모델링), 이를 전이하여 파인튜닝하고 Task를 수행 (NLP Task)
Pre-training data
pre-train 절차는 주로 언어 모델 사전 훈련에 고나한 기존 문헌을 따름
BookCorpus (800M 단어)
English Wikipedia (2500M 단어) > text passage (list, table, header 무시)
긴 연속 sequence 추출을 위해 document-level corpus가 shuffled sentence-level corpus (Billion Word Benchmaek)보다 중요
3.2 Fine-tuning BERT
Transformer의 self-attention mechanism이 정확한 input과 output을 교환하면서 BERT의 많은 후속 작업을 모델링하도록 허용하면서 fine-tuning이 단순화됨


각각의 작업을 위해 일어나는 input과 output을 BERT에 연결하고 end-to-end로 모든 parameter를 fine-tuning 함
input에 pre-training의 sentence A, B은 아래와 유사하다.
(1) paragraphing sentence pairs
(2) hypothesis-premise pair in entailment
(3) question-passage pairs in QA
(4) 퇴보한 text-pair in text 분류 or sequence tagging
output에 token representation은 token-level 작업의 output layer에 반영됨
ex) sequence tagging, QA
[CLS] representation은 분류의 output layer에 반영됨
ex) entailment, sentiment analysis
pre-training에 비해 fine-tuning은 가벼움
4 Experiments
BERT의 fine-tuning 결과 (11 NLP task)
4.1 GLUE
General Language Understanding Evaluation
다양한 자연어 이해 작업
fine-tuning을 하기 위해,
input sequence의 final hidden vector(𝐶∈𝑅^𝐻)가 총합으로 첫 input token ([CLS])에 대응
(input sequence: single sentence & sentence pair)
fine-tuning 중,
새로운 parameter는 분류 layer 가중치 (W∈𝑅^(K∗𝐻))
- K: label 개수
- C, W로 기존 분류 loss 계산 log(softmax(CW^T))
- batch size = 32
- fine-tune 3 epoch (ALL GLUE task data) > 이때 Dev set에 최고의 fine-tuning learning rate 선정
BERT_LARGE가 작은 데이터셋에 fine-tuning이 안정적이지 않음
그래서 몇몇 랜덤 재시작 실행, Dev set에 최적의 모델 선정
랜덤 재시작
- 같은 pre-trained checkpoint 이용
- 하지만 다른 fine-tuning data shuffling과 classifier layer 초기화

BERT의 결과가 좋음
적은 데이터에서도 BERT_LARGE가 BERT_BASE보다 좋음
4.2 SQuAD v1.1
Stanford Question Answering Dataset (100K crowd sourced QA pairs)
> passage 안의 answer text span 예측
QA 작업에서,
input question (A embedding 이용)과 passage (B embedding 이용)를 single packed sequence로 나타냄

i단어가 answer span의 시작이 되는지 가능성 계산은 T_i와 S의 dot
비슷한 공식이 answer span의 끝에도 사용

- 위치 i에서 j까지 후보 span의 값 S ∗ T_i + E ∗ T_j
- j scoring span의 최대값은 (j >= i)는 예측에 사용
training 목표: 올바른 시작과 끝 위치의 log-likelihood의 합
- 3 epoch로 fine-tuning (learning rate = 5e-5)
- batch size = 32
training에 public data 아무거나 사용 가능
- fine-tuning 첫번째 TriviaQA
- fine-tuning 다음 SQuAD

BERT의 결과가 가장 좋음
4.3 SQuAD v2.0
SQuAD v1.1 확장
짧은 답변이 아닌 더 현실적인 답변
- no-answer span: 𝑆_𝑛𝑢𝑙𝑙=𝑆𝐶+𝐸𝐶
- 𝑆_(𝑖 ̂, 𝑗)=〖𝑚𝑎𝑥〗_(𝑗≥𝑖) 𝑆𝑇_𝑖+𝑆𝑇_𝑗
- 𝑆_(𝑖 ̂, 𝑗)>𝑆_𝑛𝑢𝑙𝑙+ 𝜏 일때 예측
- threshold (𝜏) : Dev set에서 F1을 최대로 하는 선택
- TriviaQA data 사용 X
- fine-tuning 2 epoch (learning rate = 5e – 5)
- batch size = 48

4.4 SWAG
Situation with Adversarial Generation dataset (113K)
sentence pair completion examples
grounded 상식 추론 평가
문장이 주어지면 다음에 타당한 문장 4개중 선택
- fine-tuning시, 4개의 input sequence로 구성 (주어진 문장과 합쳐서: A + B)
- [CLS] token dot > C: softmax layer의 정규화된 선택값
- fine-tuning 3 epoch (learning rate = 2e – 5)
- batch size = 16

5. Ablation Studies
5.1 Effect of Pre-training Tasks
5.2 Effect of Model Size
5.3 Feature-based Approaches with BERT
6. Conclusion
BERT, GPT ELMo차이

ELMo: left-to-right, right-to-left 문맥을 각각 독립적으로 계산하여 접합한 형태
OpenAI GPT: left-to-right로만 계산
> 두 방법 모두 공통적으로 양방향 문맥 등을 보지 못하여 충분히 언어 표현을 하지 못함
BERT: 사전 학습을 위해 두 가지 방법 (Masked Language Model(MLM)과 Next Sentence Prediction(NSP))를 사용
이 방법들은 BERT가 양방향으로 학습되어 문맥을 더 잘 파악함
'논문 > review' 카테고리의 다른 글
| Sequence to Sequence Learning with Neural Networks (0) | 2024.08.28 |
|---|---|
| ImageNet Classification with Deep Convolutional Neural Networks (0) | 2024.08.07 |
| Very Deep Convolutional Networks For Large-Scale Image Recognition (0) | 2024.07.03 |
| Attention Is All You Need 리뷰 (0) | 2024.06.22 |
| Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation 리뷰 (0) | 2022.08.19 |



