문제 분석(목적)
이전 시점을 이용해서 현재 시점의 데이터를 예측하는 model 사용하기
처음 진행해보는 과정인만큼 가장 쉽게 적용해볼 수 있는 데이터에 적용해본 후 복잡하고 큰 데이터셋에 대해 진행할 예정
데이터의 순서에 의해 영향을 받는 시계열 데이터의 경우에 좋은 효과를 보이는 RNN, LSTM, GRU와 같은 model 이용해보기
데이터 선택
Kaggle Dataset에서 Time Series 중 Electric Production Dataset
데이터들을 고를 중 내가 원하는 방법으로 분석하기에 가장 기본적인 데이터 구조를 갖는다고 생각하여 선택하게 됨
데이터셋에 대한 설명은 추가로 없었음
데이터 수집
pd.read_csv를 이용하여 데이터프레임 형태로 불러오려 했으나 시간 데이터를 정리된 형태로 한번에 불러오기 위해
parse_dates=[‘DATE’]
index_col=‘DATE’
로 조건을 설정했더니 Series 형태가 되어 데이터프레임을 직접 바꾸어야 했다
데이터 전처리
먼저 DATE와 IPG2211A2N이라는 복잡한 열이름으로 되어있어 date와 EP로 열이름을 변경한다
현재 데이터의 분포 확인하기 위해 전체 데이터 분포 그래프

시간 열을 제외하고 Electric Production 열만 존재해서 정규화를 진행하지 않아도 된다고 생각했는데
이후 loss 그래프를 확인했을 때 이해하기 어려워서 정규화를 진행하기로 함
정규화는 sklearn에서 MinMaxScaler를 이용하여 0~1사이 값으로 한다.
AI 모델
Vector autoregression model 관련 논문을 읽던 중 이전 시점을 이용해서 현재 시점의 데이터를 예측하는 model을 사용하는 것을 보았다. 그래서 다른 추가 변수 없이 이전 시점들의 y 값과 현재 시점의 y을 통해 다음 시점 y+1의 값을 예측하는 모델을 만든다.
데이터의 순서에 의해 영향을 받으므로 이에 좋은 효과를 보이는 RNN, LSTM, GRU와 같은 model을 사용한다.
* 데이터 재구성
이전 3개의 시점의 데이터와 현재 데이터를 입력으로 받아 다음 시점의 데이터를 예측한다.
이때 각 열이름은 EP_t-3, EP_t-2, EP_t-1, EP_t-0, EP_t+1로 한다. -> NaN 발생
NaN이 들어간 행은 삭제한다.
* 데이터 분할
시계열 데이터의 경우 무작위로 선택하면 시간의 흐름이 망가져서 데이터셋 분리를 끊어서 진행한다.
데이터 분할을 약 train data: validation data: test data = 2:1:1로 한다.
아래의 그림은 train data, validation data, test data를 다른 색으로 시각화한 그래프이다.

데이터프레임에 입력변수와 출력변수를 분리한다
x_train, y_train
x_valid, y_valid
x_test, y_test
* 모델링
GRU
LSTM
optimizer=Adam
epoch=100
결과
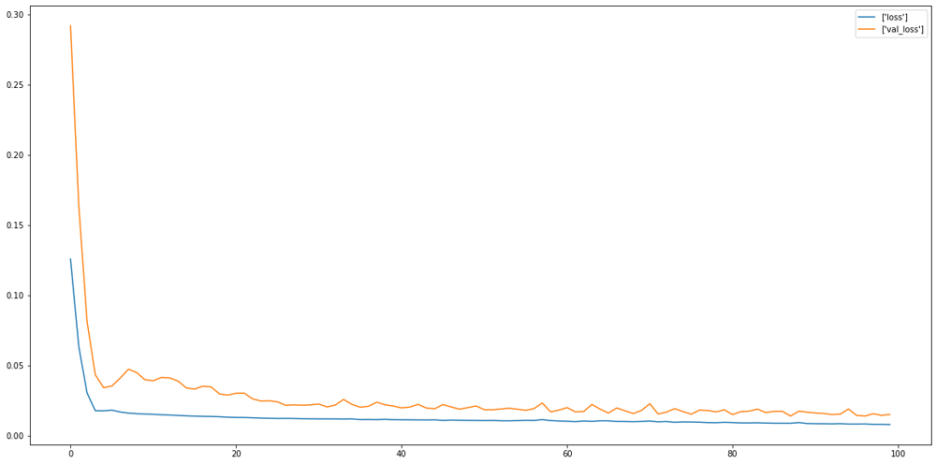
훈련의 결과 train data와 validation data의 loss값을 시각화하면 아래와 같다.
Test data의 실제값과 예측값으로 데이터프레임을 만든다
정규화 전의 값으로 inverse_transform을 진행한다.
Test data와 실제값과 예측값에 대한 시각화를 진행한다.
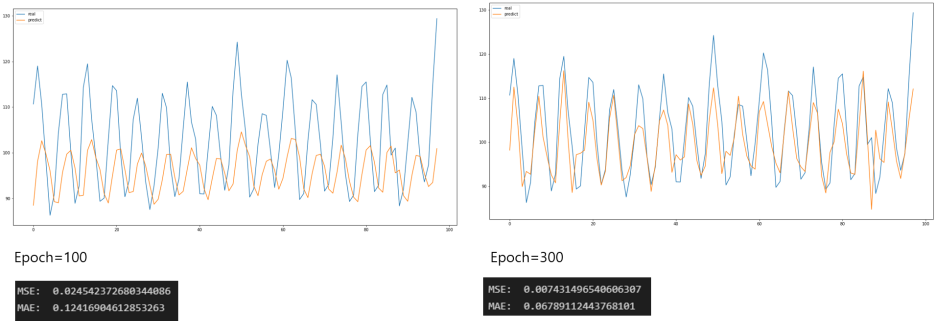
epoch=100에서 레이어 16, 64를 각각 추가한 결과

epoch=300에서 레이어 16, 64를 각각 추가한 결과

다양한 모델을 사용하기 위해 GRU 1 layer만 사용하는 것이 아닌 아래의 방법들을 이용해 보았다.
- GRU를 LSTM으로 대체
- 정규화 없앤 경우
- Layer 추가
- Epoch값 변경
- Early stopping
하지만 해당 프로젝트의 결과보다 좋지 않은 결과이거나 비슷한 결과값이 나왔다.
참고
LSTM으로 진행한 결과

기여
앞으로 큰 데이터셋에 적용해보면 더 좋은 결과가 나오길 기대한다.
데이터 전처리 과정에서 단순히 정규화만이 아닌 시계열 데이터에서 다양한 방법을 적용해볼만 하다.
LSTM과 GRU의 결과가 비슷해서 적용하지 않았지만 앙상블의 과정을 거치는 것도 앞으로 적용해볼만 할 것이다.
이전 값만 이용한 model이 아닌 고정된 다른 변수가 있는 경우도 적용해볼 것이다.
링크
https://github.com/ornni/Projects/blob/main/GRU/GRU_project_electric_production_data_code.md
Projects/GRU/GRU_project_electric_production_data_code.md at main · ornni/Projects
Deep Learning Algorithm. Contribute to ornni/Projects development by creating an account on GitHub.
github.com
'프로젝트' 카테고리의 다른 글
| Transformer - Translation (0) | 2024.07.31 |
|---|