파일 정리
(데이터 파일)
- data
- preprocessed_data
- result
(코드 파일)
- preprocessing_code
-modeling_code
0. directory 확인
1. load data
데이터 불러오기
2. data preprocessing
2-1. data check
- 각 변수 의미 확인
| Variable | Definition | Key |
| survival | Survival | 0 = No 1 = Yes |
| pclass | Ticket class A proxy for socio-economic status (SES) |
1 = 1st 2 = 2nd 3 = 3rd |
| sex | Sex | |
| Age | Age in years Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5 |
|
| sibsp | # of siblings / spouses aboard the Titanic The dataset defines family relations in this way... Sibling = brother, sister, stepbrother, stepsister Spouse = husband, wife (mistresses and fiancés were ignored) |
|
| parch | # of parents / children aboard the Titanic The dataset defines family relations in this way... Parent = mother, father Child = daughter, son, stepdaughter, stepson Some children travelled only with a nanny, therefore parch=0 for them. |
|
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown S = Southampton |
- 균형/불균형 데이터 확인
0: 549, 1:342로 크게 불균형하지 않다고 판단
- 범주형 변수 정리
sex 변수의 경우 male:0, female:1
embarked 변수의 경우 C: 0, Q: 1, S: 2
age변수의 경우 나이대로 범주화
- 기술통계량 확인 (Histogram)
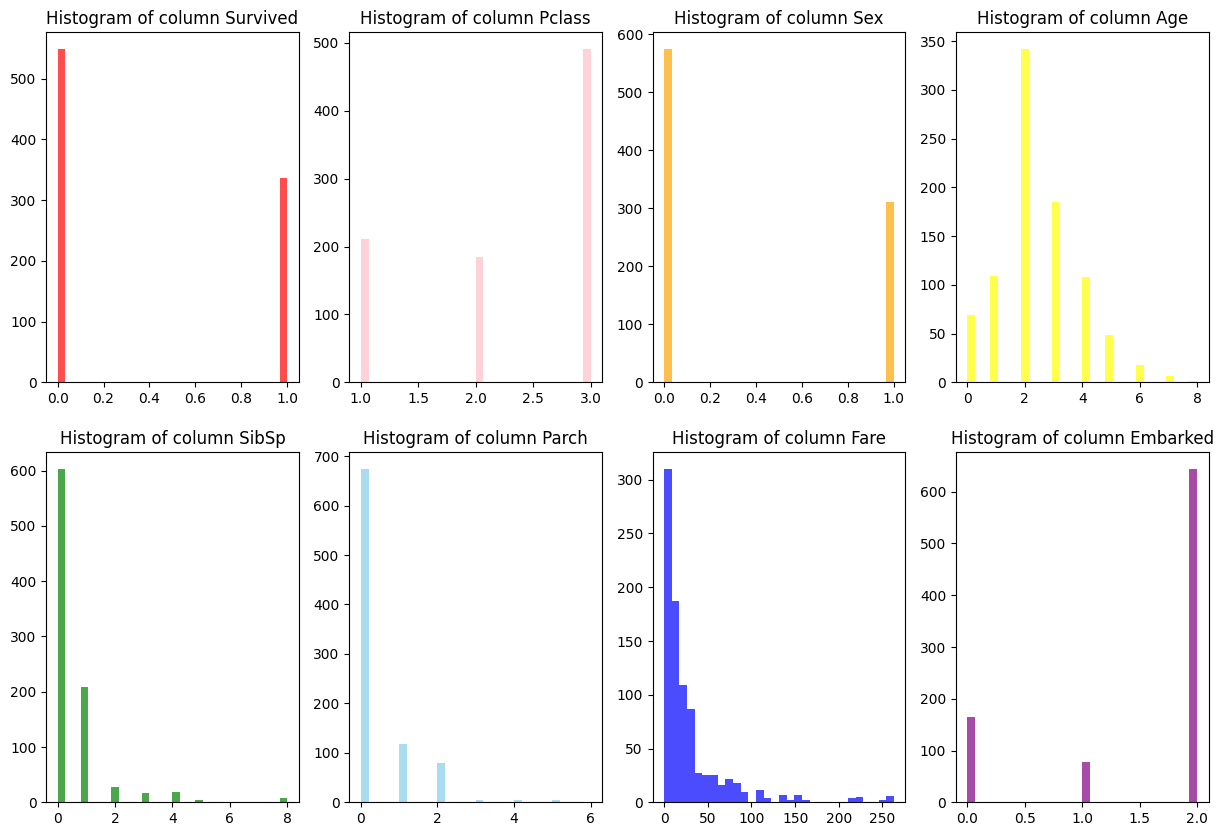
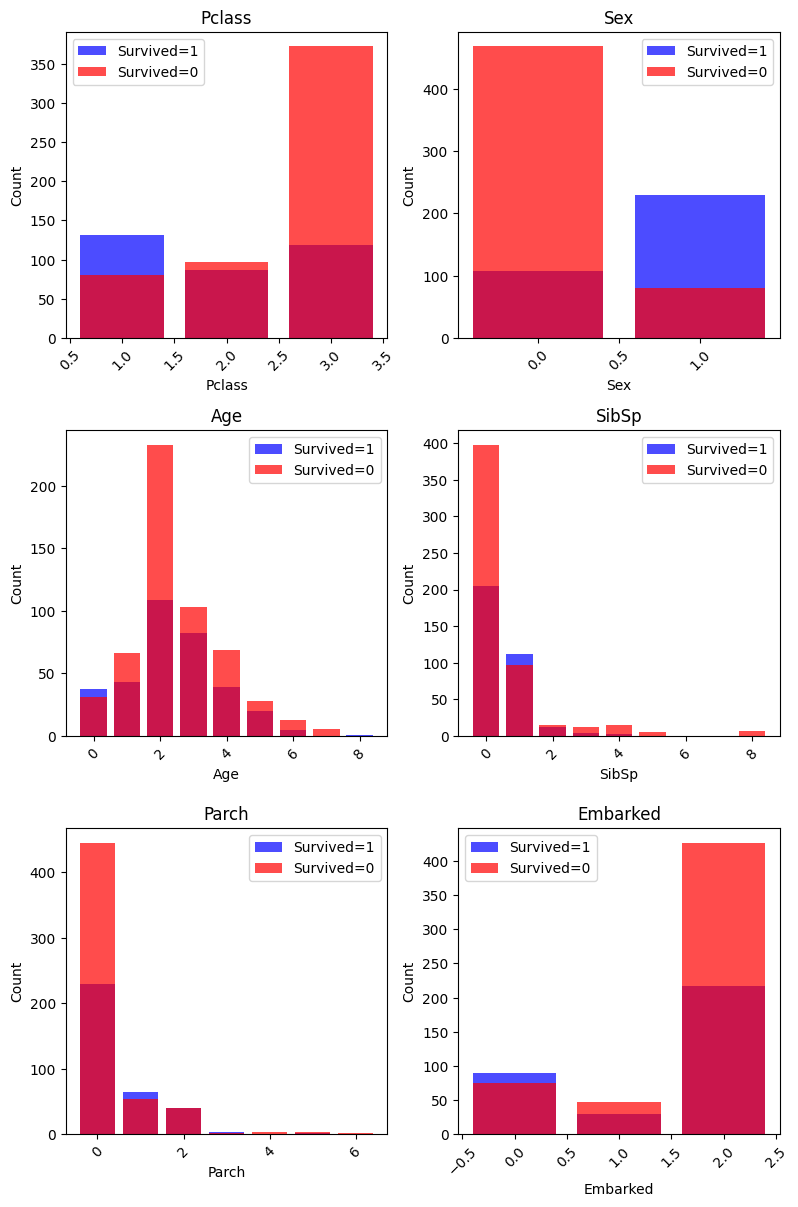
- survival 별 변수 개수 확인
- 상관관계 확인
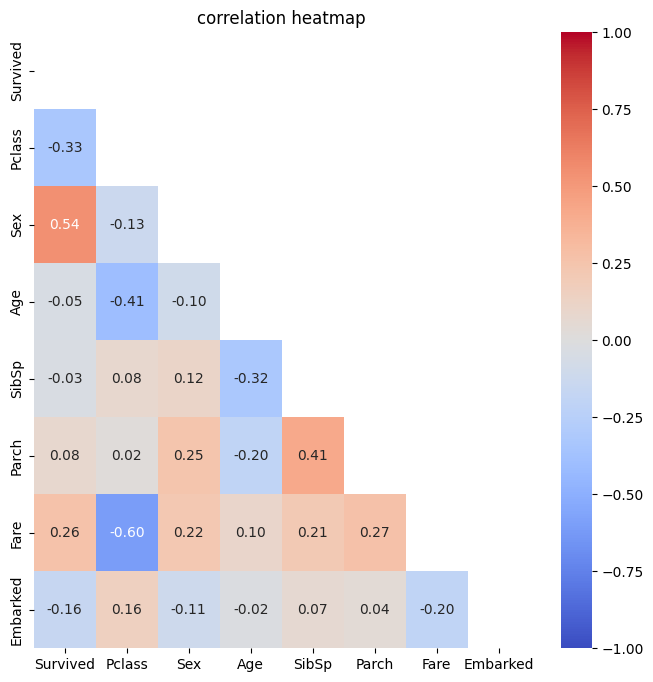
열별로 상관관계 크게 없음
2-2. data preprocessing
- 이상치 확인
히스토그램 확인 결과 Fare열 boxplot 확인 필요
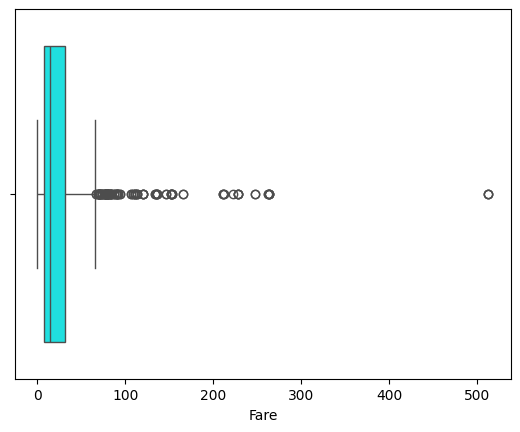
400이상의 값은 이상치라고 판단하여 제거
나머지 변수들은 이상치까지 생각하기 힘들다고 판단함
- 결측치 제거
train 데이터에 age와 embarked에서 나타남
test 데이터에 age와 fare에서 나타남
- embarked의 경우 개수가 몇개 되지 않으므로 제거
- age의 경우 Linear Regression으로 결측체 대체
- fare의 경우 median으로 결측치 대체
- 정규화
연속형 변수인 Fare에 Min-Max Scaling 정규화 진행
z-score은 음수가 나올 수 있는데, 가격은 음수가 나올 수 없으므로 min-max scaling 적용
~~여기까지 진행 후 preprocessed_data 파일에 preprocessed_train.csv, preprocessed_test.csv로 저장~~
- 데이터 분할
train 데이터를 x_train, x_val, y_train, y_val로 분할
test 데이터를 x_test로 분할
3. 모델링
- 데이터 분할
train데이터를 train데이터와 validation데이터로 나눈 후 확인 (test_size = 0.2)
- 모델링
Naive Bayes
Decision Tree
Random Forest
Support Vector Machine
Logistic Regression
KNN
4. 결과
Naive Bayes
accuracy : 0.7865168539325843
MAE: 0.21348314606741572
MSE: 0.21348314606741572
Decision Tree
accuracy : 0.7808988764044944
MAE: 0.21910112359550563
MSE: 0.21910112359550563
Random Forest
accuracy : 0.8314606741573034
MAE: 0.16853932584269662
MSE: 0.16853932584269662
Support Vector Machine
accuracy : 0.8370786516853933
MAE: 0.16292134831460675
MSE: 0.16292134831460675
Logistic Regression
accuracy : 0.8146067415730337
MAE: 0.1853932584269663
MSE: 0.1853932584269663
KNN
accuracy : 0.7921348314606742
MAE: 0.20786516853932585
MSE: 0.20786516853932585
5. 제출
모든 모델에 대해서 predict 진행한 후 csv 파일로 저장하여 제출
Naive Bayes: 0.74401
Decision Tree: 0.76076
Random Forest: 0.77751
Support Vector Machine: 0.78708
Logistic Regression: 0.76315
KNN: 0.72727
링크
https://github.com/ornni/kaggle/tree/main/Titanic%20-%20Machine%20Learning%20from%20Disaster
kaggle/Titanic - Machine Learning from Disaster at main · ornni/kaggle
repository for recording kaggle codes. Contribute to ornni/kaggle development by creating an account on GitHub.
github.com
'Kaggle' 카테고리의 다른 글
| Mobile Price Classification (0) | 2024.10.30 |
|---|---|
| Regression with a Flood Prediction Dataset (1) | 2024.05.25 |

